
Identiverse Has 100 Vendors Solving Agent Identity at the Wrong Layer
Identiverse 2026 is happening this week. The agenda is what you would expect from the industry’s flagship identity conference. Keynotes from Okta, Ping, Microsoft, SailPoint, BeyondTrust, CyberArk, ForgeRock, and Saviynt. Booths from every vendor in the IAM space. Sessions on agent identity, agent authorization, agent governance. The word “agent” appears in dozens of talks. Vendors have rebranded their service-principal products as “agent identity platforms.” Conference-floor demos walk through agent provisioning, agent SSO, agent token rotation.
100% of these pitches place agent identity at the application layer. No matter how creative the spin on their identity solution is, each is fundamentally flawed.
This is the part of the moment that deserves to be named directly. Every vendor at Identiverse is solving the same problem the same way: extend an existing application-layer identity primitive to cover agents. OAuth grants get repurposed. Service principals get rebranded. SAML federations get pointed at agent endpoints. The directory model that has run human and workload identity for thirty years is being stretched to cover a new actor type.
There is one proposal in the agent identity space that does the opposite. The Agent Transfer Protocol places agent identity at the transport layer. One protocol. Free. Open standard. Working code. And the architectural decision that puts identity in transport is the one that disrupts every vendor pitch on the conference floor.
This article is about why those two layers are different, why the choice between them is structural rather than stylistic, and why a single open protocol has the leverage to disrupt a hundred well-funded vendor approaches at once.
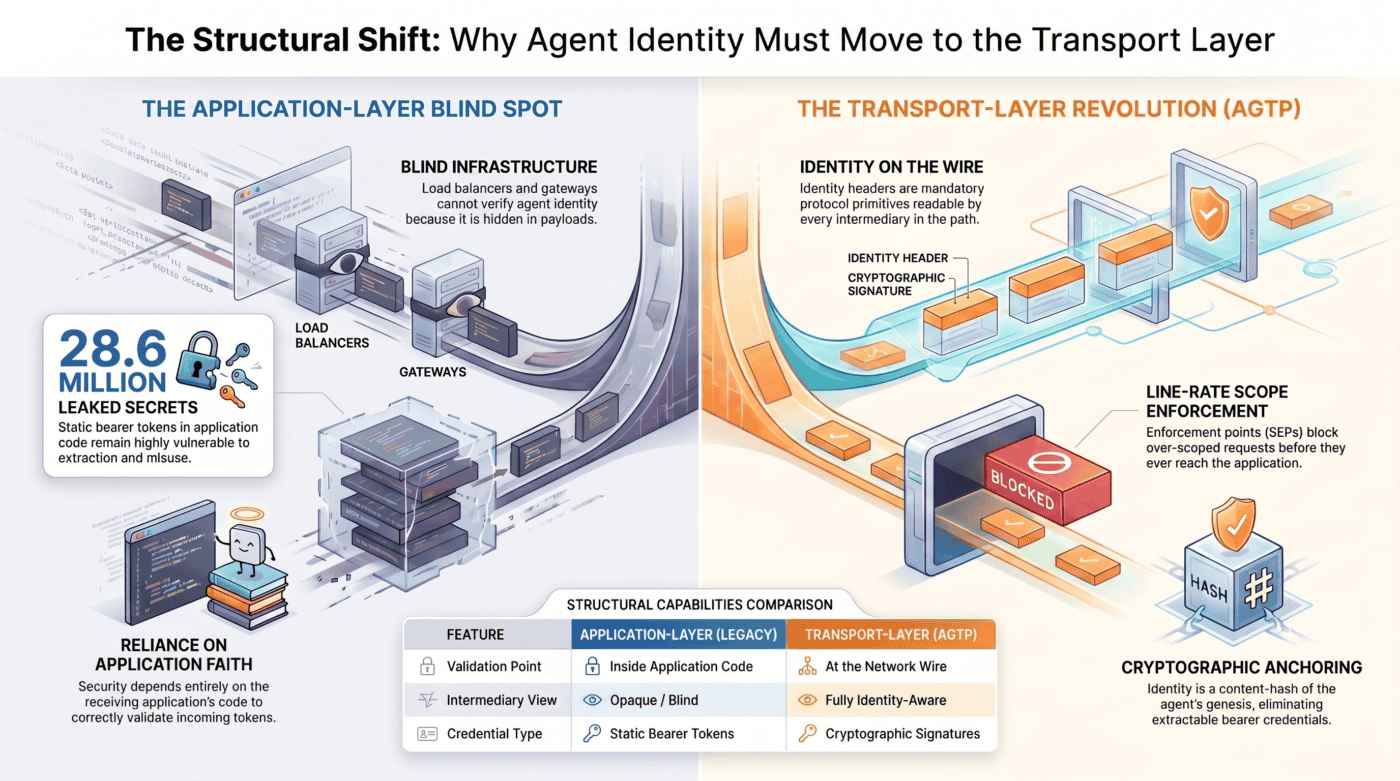
Application-layer identity, in plain terms
Application-layer identity means the identity claim travels in the body of the request or in a header the transport has no opinion about. The transport sees bytes. The application parses the bytes, validates the identity claim against whatever issuer it trusts, and decides what to do.
In practice, this looks like OAuth bearer tokens in the Authorization header. The token is a credential the application unpacks. The transport (HTTP, gRPC, whatever) carries the bearer as an opaque payload. The HTTP server has no concept of who is calling. It has a request and a payload. The decision about identity occurs within the application code, after the transport has done its job.
This is the model every vendor at Identiverse is shipping. It works for humans because they authenticate once per session, and the application has time to validate the bearer token on each request. It works for workloads because workloads run inside trust boundaries the operator controls. It is the right answer for the problems the IAM industry built itself around.
It is also the wrong answer for agents, and the wrongness has structural consequences that compound.
When identity lives at the application layer, every intermediary between the client and the server is identity-blind. The load balancer cannot enforce scope. The API gateway cannot validate the agent’s manifest. The audit logger cannot bind a request to a verified agent identity because validation has not yet occurred. The network sees a POST with a bearer header. Every piece of infrastructure between the two endpoints operates on the faith that the application at the far end will validate things correctly.
For human and workload traffic, this is fine. The traffic mostly stays within a single trust boundary. The application at the other end can be trusted because the operator runs it. The compromise surface is bounded by the perimeter.
For agent traffic, the compromise surface is unbounded. Agents cross organizational boundaries. Agents delegate to other agents. Agents act on behalf of principals the receiving organization may have no relationship with. Every intermediary in that path is operating on faith, and faith is the wrong primitive for a regulated commerce surface.
Transport-layer identity, in plain terms
Transport-layer identity means the identity claim is a property of the wire itself. The protocol carries identity headers as mandatory primitives. Every intermediary can read them. Every receiver can verify them before any application code runs.
AGTP is the only open agent protocol that makes this choice. Every AGTP request carries Agent-ID, Owner-ID, and Authority-Scope as wire-level headers. The identity is anchored to a signed Agent Genesis whose 256-bit hash is the Agent-ID. The verification is cryptographic and happens against a public trust path. No third-party token issuer required. No real-time IdP lookup required. No application code required.
The consequences ripple through every component of the agent infrastructure stack.
Scope Enforcement Points (SEPs) at the wire can refuse over-scoped requests before they ever reach the application. The SEP reads the Authority-Scope header, checks it against the agent’s certificate commitment, and returns 455 Scope Violation at line rate. The application stays uninvolved. Misconfigured applications cannot accidentally allow what the protocol forbids.
Governance zones get enforced the same way. The AGTP-Zone-ID header travels with every request. SEPs at zone boundaries refuse cross-zone traffic that policy forbids, returning 457 Zone Violation. Jurisdictional separation moves from a paper concern to a packet-level property.
Attribution-Records are produced as protocol output, signed with the agent’s certificate-bound key, and written to append-only transparency logs aligned with RFC 9162 and SCITT (RFC 9943). The audit trail is structural. The records compose across organizations because the format is shared. No vendor-specific log reconciliation required.
Discovery happens through ANS, the protocol-native agent name service. Queries return signed, ranked results carrying canonical Agent-IDs and trust tiers. Federation preserves provenance across operators. The discovery layer participates in identity management rather than leaking metadata to anyone who asks.
Each of these is a property that exists because identity is at the transport layer. None of them exist when identity lives in an opaque token at the application layer. The architectural decision compounds upward into every higher-level capability.
Six months of receipts
The Identiverse argument about layers could be left at the structural level. The empirical record makes it harder to ignore.
DevFortress recently published a deep digest covering six months of AI agent credential incidents from December 2025 through June 2026. The pattern across every incident in the digest is the same: a real, usable credential existed in a layer the attacker could reach. The governance and detection tools assume this is inevitable. The digest argues otherwise.
The breach inventory maps onto exactly the three layers the agent stack is being built across.
At the application layer (developer tools, CI/CD, source code, enterprise platforms), Claude Code CVE-2026-21852 had an API key stolen before the trust dialog displayed. Oracle PeopleSoft was breached by ShinyHunters with zero authentication required, exposing 500,000 student records across more than 100 organizations. A no-auth API endpoint is, structurally, a real credential exposed to the network.
At the API layer (OAuth tokens, API keys, credentials in transit, deployment platforms), Salesloft-Drift OAuth tokens survived MFA challenges and remained under attacker control for 5 months. Vercel environment variables sold for two million dollars on BreachForums. 28.6 million secrets were committed to GitHub in 2025 alone. The LiteLLM supply chain breach pulled PyPI credentials through a compromised security scanner. 64% of credentials leaked in 2022 remain active in 2026.
At the tool layer (MCP configs, skill registries, agent runtime, cross-task credential access), the Moltbook breach exposed 1.5 million tokens through CVE-2026-25253. ClawHavoc placed 1,184 malicious skills in agent registries. OX Security documented 14 CVEs attributable to a single root cause. 93% of AI agent projects ship with unscoped API keys. 57% of enterprise identity activity is invisible to IAM tooling.
The common thread is structural. Every credential in every layer was reachable. Every detection product (Snyk, RAMPART, GitGuardian, Qualys) found the credentials after they were committed. Every governance product (Okta, 1Password, CyberArk, Orchid) controlled access to credentials after they existed. Every response product (Arctic Wolf, Palo Alto, CrowdStrike, Salt) acted on breach signals after compromise. The entire market is organized around the assumption that real, reachable credentials are an unavoidable part of the stack.
The application-layer identity model that every Identiverse vendor is selling this week is the model that produced this six-month record. Every product they ship operates on the assumption that the credential exists somewhere in a reachable layer, and that the right thing to do is detect, govern, or respond to its presence after it gets there.
The transport-layer model removes the assumption. When identity is cryptographically derived at the transport layer, anchored to a content-hashed Genesis, and verified per-request against a public trust path, there is no static bearer for an attacker to extract. The 28.6 million secrets in GitHub are 28.6 million bearer credentials. An AGTP-resident agent has no equivalent artifact to leak, because its identity is the hash of its origin document and the signature on its certificate, never a token stored in an environment variable or a config file.
This is what the choice of layer means in practice. Application-layer identity produces the kind of breach inventory the last six months have produced. Transport-layer identity removes the class of credential that those breaches exploited.
The three “layers” are one layer
The DevFortress digest organizes the breach inventory into three layers (application, API, AI agent), and the organization is useful for taxonomic purposes. It is misleading about the architecture.
Structurally, all three layers are application-layer software running on HTTP. The developer tools, CI/CD pipelines, and enterprise platforms in the application-layer bucket are HTTP services. The OAuth flows, API keys in transit, and deployment platforms in the API-layer bucket are HTTP services. The MCP configs, skill registries, and agent runtimes in the AI-agent-layer bucket are HTTP services. MCP itself is an application protocol that runs on top of HTTP. Agent runtimes make HTTP calls. Skill registries serve HTTP endpoints. The “tool layer” is application-layer code wearing new marketing.
This is the part of the conversation that needs to be precise. When somebody refers to “the AI agent layer” as if it is structurally distinct, they are using a category label that has marketing salience but lacks architectural meaning. The category is real (these are products built for the agent ecosystem). The layer they live at is the same layer everything else lives at: above HTTP, in application code, with the transport identity-blind beneath them.
Every breach in the DevFortress digest exploited this fact. The credential was somewhere in the application stack. The transport had no view of it. The intermediaries had no view of it. The detection product found it later, after it had already been used.
AGTP is the only dedicated substrate that breaks this pattern. The protocol runs on port 4480 with mutual TLS. It avoids HTTP entirely. It carries identity, scope, attribution, and zone as wire-level primitives that any AGTP-aware intermediary can read. It is built exclusively for agent traffic, with three structural commitments that no application-layer system can replicate.
Exclusive use for agents. The protocol exists to move agent traffic. The semantics, headers, and verbs are all agent-shaped. The substrate is purpose-built rather than retrofitted.
Known location. Every agent has a canonical address that can be derived from its identity. Discovery is built into the protocol. Agents are findable by capability, by Agent-ID, and by URI form, through a federated name service rather than through vendor marketplaces.
Canonical identity. The Agent-ID is the SHA-256 hash of the signed Genesis document. The identity is the content. No directory, no token, no operator can alter it. There is no bearer credential to leak, because there is no bearer credential.
Every other agent infrastructure proposal on the market is a layer on top of HTTP. AGTP is the only layer below it.
Why the choice is structural
This is the part of the conversation that gets lost in vendor marketing, so it is worth being precise about. The difference between application-layer and transport-layer identity is more than a feature comparison. It is a category difference.
An application-layer identity system can ship better tokens, libraries, SDKs, and dashboards. The vendor can iterate on the experience indefinitely. What the vendor cannot do is move the validation point. The transport stays identity-blind by definition, which means every intermediary in the path stays uninformed about who is calling. No amount of application-layer iteration changes that property.
A transport-layer identity system inverts the situation. The transport carries the identity claim. Every intermediary can read it. The validation point sits at the wire, where the SEP can refuse requests before any application sees them. The vendor experience can still be excellent (libraries, SDKs, dashboards, registry tooling), but the structural property the application-layer model cannot reach is delivered for free.
This is why the choice cannot be papered over with better tooling. A vendor at Identiverse can build a beautiful application-layer agent identity product. It will still leave intermediaries blind. It will still require trust in the application’s correctness for enforcement. It will still produce vendor-specific audit trails that fail to compose across organizations. The structural limits are baked into the layer the vendor chose.
The leverage of putting identity at the transport is that it changes what every higher-level component can do. Load balancers become identity-aware. Gateways become scope-aware. Audit systems become structurally correct. Marketplaces become protocol-native. Delegation becomes cryptographically composable. Each of these is a property the application-layer model can approximate but cannot deliver structurally.
Why one protocol disrupts a hundred vendor pitches
The math is honest. The IAM industry has spent enormous resources on application-layer agent identity. Hundreds of products. Thousands of engineers. Billions of dollars of investment. The combined output of that effort is a category of agent identity that operates at the wrong layer and inherits that layer’s structural limits.
The reason one protocol can disrupt a hundred vendor pitches is that it changes the structural property that the vendor pitches all share. Every Identiverse vendor’s agent identity offering is improved by AGTP underneath, because the transport-layer identity makes every higher-level claim more verifiable. Every Identiverse vendor’s agent identity offering is also threatened by AGTP underneath, because the transport-layer identity makes the vendor’s directory the dependent layer rather than the authoritative one.
This is the same shape SMTP took in the mail wars of the 1980s. Proprietary mail systems held mail in their databases. SMTP carried mail as self-contained envelopes any compliant server could read. The proprietary systems retreated to being interfaces over the open substrate. The substrate won.
The IAM vendors at Identiverse can either build on the AGTP substrate (extending their offerings to compose with transport-layer identity) or compete with it (insisting that application-layer identity is sufficient). The first option keeps them relevant. The second option positions them for the SMTP exit, where the substrate handles the structural work, and the vendor’s product serves as an interface over the substrate.
The vendors that figure this out first will dominate the post-AGTP IAM market. The vendors that miss it will spend the second half of the decade explaining why their application-layer products keep failing audits, failing to meet logging requirements, and producing forensic gaps that the transport-layer alternative closes by design.
What an enterprise should be asking on the conference floor
If you are walking the Identiverse floor this week, the question that separates real agent identity from rebranded service-principal products is structural. It has one form.
“Does your agent identity ride on the wire, or in the application?”
If the answer is “in the application,” you are looking at a product that will leave every intermediary blind, require application-layer policy enforcement, produce vendor-specific audit trails, and fail to compose with agents at other organizations without bilateral integration. This is the entire category at Identiverse this year.
If the answer is “on the wire,” you are looking at AGTP, or something derived from AGTP. There is currently one such answer in the agent infrastructure conversation. The protocol is open. The reference implementation is Python. The registry is live. The port (4480) is registered with IANA. The URI scheme (agtp://) is reserved. The companion drafts cover trust, identifiers, logging, discovery, composition, session, agent certificates, and merchant identity. The work is happening at the IETF on the independent submission stream.
The question is whether to add a transport-layer foundation to whatever IAM stack you are already running, or whether to keep buying application-layer products that will be obsolete the moment the substrate question gets resolved.
The substrate question always gets resolved. SMTP. TLS. DNS. Certificate Transparency. Every infrastructure-level fight in networking history has ended the same way: the open substrate that handles the structural job becomes the foundation, and the vendor products built on top of it become interfaces over the substrate. The agent identity fight will end the same way.
The vendors selling application-layer agent identity at Identiverse 2026 are selling products that will need to compose with AGTP within three years. The buyers walking the floor have a choice. Buy the application-layer product and add the substrate underneath later. Or recognize that the substrate is the structural layer and architect around it from the start.
The substrate is open. The vendors will catch up or fade. Transport now carries identity, regardless of whether the application layer acknowledges it.
That is what one universal free protocol does to a hundred vendor pitches.
If you find this content valuable, please share it with your network.
Follow me for daily insights.
Book me to speak at your next event.
Start managing your agents for free.
Chris Hood is an AI strategist and author of the #1 Amazon Best Seller Infailible and Customer Transformation, and has been recognized as one of the Top 30 Global Gurus for Customer Experience. His latest book, Unmapping Customer Journeys, is available now!