
How Agentic Resource Discovery Lives on the Agent Transfer Protocol
Google, Microsoft, and Hugging Face published the Agentic Resource Discovery specification last week, with a launch partner roster that includes AWS, Cisco, Databricks, GitHub, GoDaddy, Nvidia, Salesforce, and Snowflake. The architecture is clean. The framing is correct. The federated, domain-anchored design is exactly what cross-organizational agent discovery has been missing. ARD is genuine progress, and the team that built it deserves the recognition they are receiving.
It is also a specification that operates entirely above the transport layer. ARD publishes catalogs as JSON files at well-known HTTPS paths. ARD registries index those catalogs and expose REST search interfaces over HTTPS. ARD’s trust manifest carries SPIFFE IDs, DIDs, and X.509 certificates as identity references, then explicitly steps out of the way once an agent has the metadata it needs to connect directly using the discovered resource’s native protocol.
This is a deliberate architectural choice and a correct one for what ARD is solving. Discovery and runtime are different concerns. Conflating them produces specifications that are harder to adopt and harder to reason about. ARD picks discovery, does it well, and hands off the runtime question to the protocols ARD catalogs: MCP, A2A, OpenAPI, and others. The handoff is the architecture’s elegance.
The substrate question that ARD leaves open is what carries those runtime protocols. Today, the answer is HTTP. Every protocol in ARD’s catalog ecosystem assumes HTTP as the transport. MCP runs over HTTP. A2A runs over HTTP. OpenAPI is, by definition, HTTP-based. ARD itself is HTTP-native: catalogs are served over HTTPS, registries are served via HTTP REST APIs, and trust manifests use HTTPS attestation URIs. The entire agent infrastructure ecosystem ARD organizes is an HTTP ecosystem.
That is the status quo, and it has costs that are becoming visible in production. The Starlette BadHost CVE disclosed in May affected thousands of agent deployments because HTTP’s substrate semantics, virtual hosting, URL reconstruction, and path-based middleware evolved for human web traffic rather than the structural properties agent traffic needs. Agent identity, authority scope, attribution, and the audit trail of who acted on whose behalf are application-layer conventions when they run over HTTP. They are conventions that an adversary can omit, forge, or bypass at the seams between the layers that make up HTTP.
The substrate question is whether agent traffic should continue to inherit HTTP’s design assumptions or whether the infrastructure ecosystem should evolve toward a substrate built for the properties agent traffic actually needs. This is a question ARD deliberately leaves open. It is the question the field has to answer next.
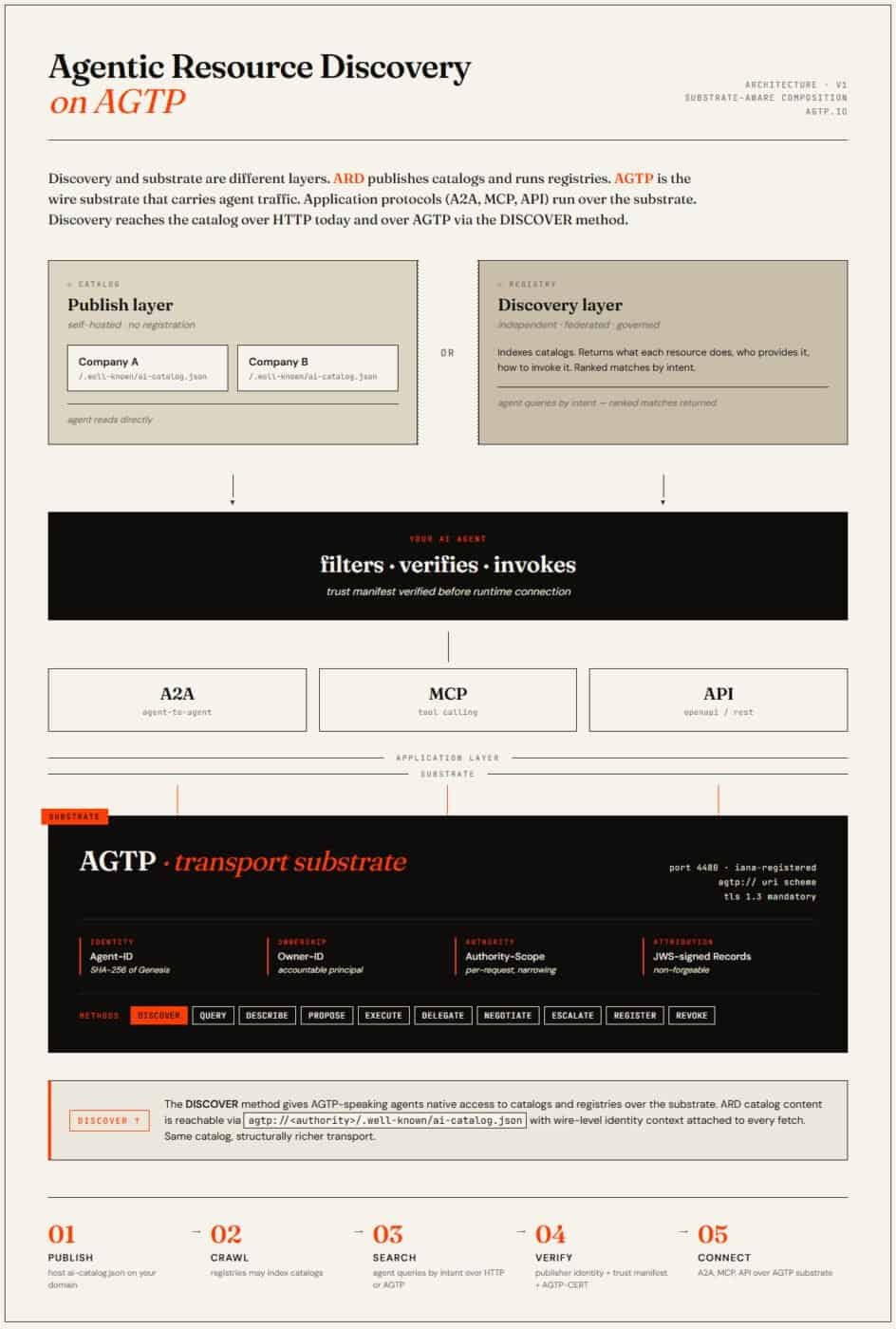
Where AGTP Fits in the Picture ARD Drew
The Agent Transfer Protocol is the proposal addressing the substrate question. AGTP defines a dedicated transport for agent traffic on IANA-registered port 4480 with the agtp:// URI scheme. The protocol carries Canonical Agent-ID, Owner-ID, Authority-Scope, and JWS-signed Attribution-Records as wire-level facts on every request and response. The agent’s identity, the principal it represents, the scope of authority it claims, and the structural attribution of who acted are foundational to the protocol rather than headers an application might choose to honor.
AGTP and ARD operate at different architectural layers. ARD answers where capabilities live and whether they can be trusted before connection. AGTP carries the connection itself with structural properties at the wire. The two compose because they were designed for different jobs.
Concretely, an agent infrastructure built on AGTP and using ARD for discovery looks like this. An organization publishes its ARD catalog at an AGTP-native location, such as agtp://agents.acme.com/catalog or agtp://{agent-id}/catalog. An AGTP-speaking agent invokes the DISCOVER method to retrieve it:
DISCOVER agtp://agents.acme.com/catalogThe request carries the agent’s Agent-ID, Owner-ID, and Authority-Scope at the wire, so the publishing endpoint can apply context-aware policy without reconstructing identity from session state or application-layer headers. The response is the ARD catalog manifest, structurally identical to what an HTTPS fetch would return, with the substrate-level context attached to the fetch.
DISCOVER is broader than catalog retrieval. Invoked against an agent or a service endpoint with no specific resource path, DISCOVER returns whatever the endpoint makes available: skills, tools, APIs, resources, or an ARD catalog if the publisher exposes one. The same method works against an MCP server running on AGTP at agtp://mcp.acme.com/discover, against a capability-listing endpoint at agtp://mcp.acme.com/catalog, or against an agent directly. The substrate handles addressing and identity; the response payload describes what is available. ARD compatibility is one of the things DISCOVER can surface, alongside the other discovery formats an endpoint chooses to expose.
Registry search works the same way. An AGTP-aware ARD registry exposes its search interface at agtp://registry.example.com/search. An agent invoking DISCOVER on that endpoint with an ARD search query in the body receives the same ranked, filtered results an HTTPS POST to /search would produce, with the requesting agent’s identity, scope, and attribution carried structurally during the search itself. The registry can return different catalog views to different agent identity classes, apply structural rate limits based on the requester’s Owner-ID, and record audit-quality attribution for every discovery interaction.
Once an agent has selected a capability from the discovery layer, a runtime connection is established. If the selected endpoint is AGTP-native, the agent invokes AGTP methods directly. If the endpoint speaks MCP or A2A, those application protocols run over the AGTP substrate the same way they currently run over HTTP. Either way, the wire-level identity context travels with every request.
What the Catalog Looks Like
An ARD catalog entry advertising an AGTP-speaking agent looks like this:
json
{
"identifier": "urn:ai:acme.com:agent:travel-concierge",
"displayName": "Travel Concierge",
"type": "application/agtp-agent+json",
"url": "agtp://agents.acme.com/travel-concierge",
"description": "AI-powered travel planning and booking agent.",
"trustManifest": {
"identity": "agtp://agents.acme.com/travel-concierge",
"identityType": "agtp",
"attestations": [
{
"type": "AGTP-CERT",
"uri": "agtp://agents.acme.com/travel-concierge/cert"
}
]
}
}ARD identifies this entry by a media type for AGTP-speaking endpoints (proposed for IANA registration as application/agtp-agent+json in the binding draft). The trust manifest carries an agtp:// identity URI, allowing trust verification through AGTP-CERT alongside any other attestations the publisher provides. The runtime URI is agtp://, signaling the substrate the agent runs on. Every URI in the entry, including the catalog URL and the certificate location, points into the AGTP substrate. From ARD’s perspective, this is a catalog entry like any other, identified by media type and resolved through the federation model ARD specifies. From AGTP’s perspective, this is a complete advertisement for an endpoint reachable over the substrate, with no HTTP layer involved.
The same organization can publish other entries advertising MCP servers or A2A agents alongside the AGTP entries. The discovery layer treats them uniformly. The substrate layer is where the architectural choice matters: whether the application protocol runs over HTTP or over AGTP determines what structural properties travel with the runtime connection.
Composition Over Competition
The authors of ARD deliberately chose to keep the specification artifact- and protocol-agnostic. This is a generous architectural choice. It means ARD can grow to include any agent runtime protocol that emerges, including substrate-level protocols like AGTP. The specification is a framework for discovery that places no constraint on what gets discovered.
That choice is what makes the composition with AGTP possible. ARD requires no change to accommodate substrate-level protocols. ARD needs a media type for AGTP-speaking endpoints, a place in the trust manifest for AGTP identity URIs, and an acknowledgment that catalog manifests can be published over protocols other than HTTPS. Each of these is incremental work that respects ARD’s existing architecture.
The IETF draft draft-hood-agtp-ard-00 defines this binding. It proposes a media type for AGTP-speaking endpoints, specifies how AGTP catalogs are published at substrate-native paths, defines the access patterns for substrate-level discovery, and addresses the security considerations that emerge from carrying wire-level identity context during catalog fetches. The binding is small because the composition is clean. ARD answers discovery. AGTP answers transport. The boundary between them is the moment the agent finishes selecting a capability and begins invoking it.
The Conversation This Opens
ARD’s launch signals that the industry has moved past the question of whether agent infrastructure needs federated discovery and into how that discovery composes with everything else. The catalog and registry layer is settling. The trust metadata layer is settling. The application protocol layer above the transport layer is fragmenting in interesting ways with MCP, A2A, and others.
The substrate question is the one that has yet to have its public conversation. ARD leaves it open because ARD’s scope ends at the discovery layer. But every agent specification published in this space implicitly assumes HTTP as the substrate, and that assumption is becoming increasingly visible in its costs.
AGTP is the proposal addressing this layer today. The binding draft shows what the answer looks like when it composes with ARD rather than competing with it. The substrate-level work is starting to appear, and the architectural conversation has to start somewhere.
What ARD built is real. The substrate it runs on is the next decision the field gets to make.
If you find this content valuable, please share it with your network.
Follow me for daily insights.
Book me to speak at your next event.
Start managing your agents for free.
Chris Hood is an AI strategist and author of the #1 Amazon Best Seller Infailible and Customer Transformation, and has been recognized as one of the Top 30 Global Gurus for Customer Experience. His latest book, Unmapping Customer Journeys, is available now!