
Rest APIs aren’t the Best Connectors for AI Agents
REST was designed in 2000. Roy Fielding published the architectural principles in his doctoral dissertation and defined the resource-oriented model that has since governed API design. GET retrieves. POST creates. PUT replaces. DELETE removes. The verbs describe operations on resources. The design assumes a developer on the other end, reading documentation, understanding HTTP semantics, and writing code that maps human intent to the right combination of verb and path.
That assumption is reasonable for the audience REST was designed to serve. But we are moving from Application Programming Interfaces to Agent Collaboration Interfaces.
You can find the complete research here: Semantic Method Naming and LLM Agent Accuracy
The core issue is simple. LLMs are built for natural language. REST was not.
AI agents are a different audience entirely. And the performance cost of asking them to use an architecture built for human developers is now measurable.
The Research
Over the past several months, I have been running a controlled benchmark through Agentic APIs to test whether the way an API is named affects how accurately AI agents select the correct endpoint. The design was straightforward: take the same capabilities, represent them in both conventional REST/CRUD form and in semantically rich intent-aligned form, then measure which performs better when frontier AI agents select among them.
The REST representation looks like what developers work with every day. POST /reservations. GET /restaurants/search. DELETE /orders/{id}. Standard HTTP verbs with resource-oriented paths.
The semantic representation uses method names aligned with what the agent is actually trying to accomplish. BOOK. FIND. CANCEL. TRACK. SUMMARIZE. The verb encodes the intent rather than the operation.
7,200 trials. Four model families. Claude Sonnet 4.6, Grok-3, GPT-4o, and Llama 3.2 3B. 18 experimental conditions.
The results are specific and statistically significant.
What the Numbers Show
In mixed-paradigm conditions, where agents encountered both REST/CRUD and semantic endpoints and had to select the right one, semantic methods outperformed REST by 10 to 29 percentage points across all three frontier models. Claude: 88% vs 59%. Grok: 88% vs 70%. GPT-4o: 80% vs 70%. The aggregate across frontier models was 85% vs 67%, with z = 3.77 and p less than 0.001.
The result was entirely absent for Llama 3.2 at 3 billion parameters. Both paradigms performed identically at around 23%. This establishes a capability threshold: the semantic naming advantage requires frontier-scale reasoning to exploit. Small models cannot leverage it.
This is important context. The findings apply specifically to frontier-scale deployments using Claude, GPT-4o, Grok, or comparable models. Organizations using smaller models for cost or privacy reasons should expect different behavior and may need different strategies.
Why It Happens: The Mechanism
Three independent experiments triangulated the same conclusion about why the difference exists.
The description-swap ablation is the most revealing. We cross-referenced the method names with the descriptions. CRUD endpoints were given agentic-style descriptions. Agentic endpoints were given CRUD-style descriptions.
When CRUD endpoints received better, more intent-aligned descriptions, accuracy collapsed. Grok fell 39 percentage points. GPT-4o fell 43 percentage points. This rules out documentation quality as the explanation. The replacement descriptions were more informative and better written than the originals. The collapse happened anyway because of the mismatch between the method name and the description style.
When agentic endpoints received CRUD-style descriptions, accuracy held. Claude showed essentially zero degradation. Grok and GPT-4o showed partial decline but retained most of their advantage.
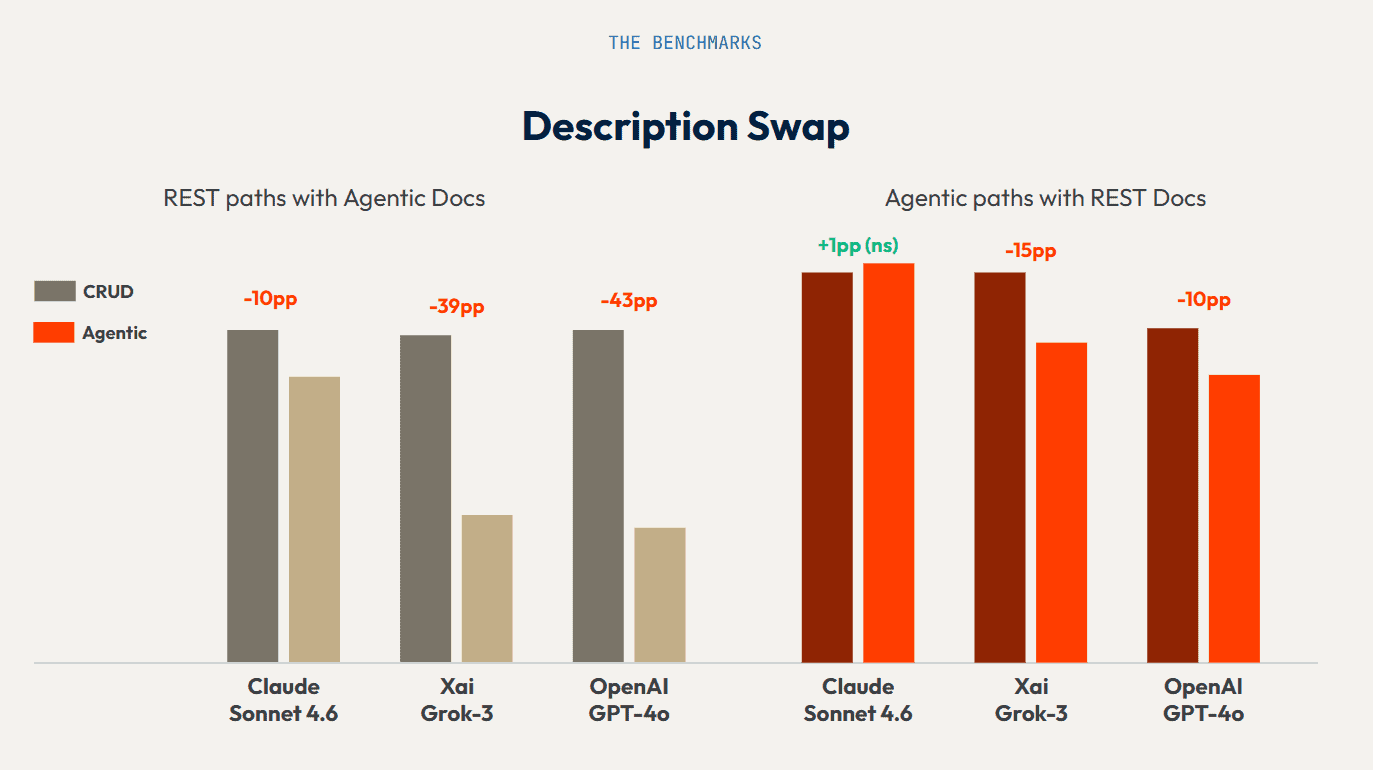
The conclusion is direct. The method name carries the intent signal. For frontier models, BOOK encodes sufficient information about what the endpoint does to survive documentation that contradicts or degrades it. POST carries no intent signal. When its documentation becomes noisy or misleading, there is nothing else to anchor selection accuracy.
The documentation analysis confirmed this from a different direction. Reducing documentation from verbose to minimal improved Claude’s selection accuracy by 13 percentage points, from 75% to 88%. Stripping description noise away and leaving the semantic method names exposed made the selection problem straightforwardly easier.
The oracle discovery experiment confirmed it from a third direction. Even when the correct endpoint was guaranteed to be present in the result set, frontier models selected agentic endpoints with higher accuracy than CRUD endpoints. The advantage persists at the selection step, independent of discovery.
The Confidence Calibration Problem
The accuracy finding is significant. The confidence calibration finding is potentially more important for organizations deploying AI agents in production.
In the description-mismatch condition, where CRUD endpoints carried mismatched descriptions, Grok reported an average confidence of 88% while achieving 30% accuracy. GPT-4o reported 87% confidence at 33% accuracy. The calibration error spiked to 60-67 percentage points.
The models were most confident when they were most wrong.

Most AI governance systems that use model-reported confidence as a signal for escalation or human review would under-escalate severely in this condition. The governance trigger is looking for low confidence to decide when to involve a human. The model is expressing high confidence. The action proceeds. The error goes uncaught.
Semantic method naming reduces this risk. The J2 calibration error for Claude was 26 percentage points versus 41 in the CRUD mismatch condition. When method names provide an accurate intent signal, overconfidence under documentation degradation is partially suppressed. The name anchors the model’s certainty even when the description misleads.
API design choices have safety implications that extend beyond accuracy statistics. Organizations deploying agents against REST APIs with imperfect or inconsistent documentation are operating with an unmeasured governance gap.
The Two-Signal Design Principle
One finding deserves specific attention because it has practical design implications.
Parametric accuracy, the ability to construct correct parameter values for an endpoint call, collapsed under reduced documentation conditions regardless of the naming paradigm. Claude: 80% to 38%. Grok: 85% to 25%. GPT-4o: 82% to 37%. Removing descriptions destroyed parametric accuracy even as it improved endpoint selection accuracy for Claude.
This separates the design problem into two distinct requirements. Semantic naming optimizes endpoint selection. Documentation quality optimizes parametric accuracy. Both matter for production usability. They respond to different design decisions.
The practical implication: lean, precise descriptions that add parameter context without introducing endpoint-disambiguation noise are the target. Verbose documentation with comprehensive descriptions, full parameter lists, and detailed type specifications may actively impede endpoint selection accuracy by introducing noise that competes with the cleaner signal from method names. Documentation should be written for parameter construction, with the understanding that endpoint selection accuracy should be handled by the naming convention.
What This Means for API Design in Agentic Systems
REST is the right architecture for human developers. The resource-oriented model, the CRUD verb vocabulary, and the documentation practices that have developed around it: these serve developers well and will continue to do so.
When the API consumer is a frontier AI agent reasoning in natural language about user goals, the architecture creates an unnecessary translation burden. POST /reservations requires the agent to infer the intent from the resource path and the HTTP verb. BOOK requires no inference. The intent is in the name.
The translation burden has a quantifiable cost. 10 to 29 percentage points of accuracy at the frontier scale. Calibration errors that produce confident, wrong decisions. Documentation degradation that collapses CRUD accuracy while barely affecting semantic accuracy.
Organizations building API interfaces that agents will consume should treat method naming as a first-class engineering decision rather than a convention inherited from REST. The research supports treating it that way.
This is the empirical foundation for the semantic method vocabulary in AGTP. The 10 to 29 percentage point accuracy lift and the resilience to documentation noise justify treating semantic naming as a design primitive rather than a stylistic preference. Implementations can preserve REST for human developer tooling while exposing intent-aligned methods to agents through the same underlying capabilities.
The question the API design community will face, as agent traffic becomes a meaningful fraction of total API consumption, is whether to design API surfaces specifically for their agent consumers or to continue inheriting design assumptions from a 25-year-old architecture built for someone else.
The performance data now exists to inform that decision.
If you find this content valuable, please share it with your network.
Follow me for daily insights.
Book me to speak at your next event.
Start managing your agents for free.
Chris Hood is an AI strategist and author of the #1 Amazon Best Seller Infailible and Customer Transformation, and has been recognized as one of the Top 30 Global Gurus for Customer Experience. His latest book, Unmapping Customer Journeys, is available now!