Introducing .agent – The Open Packaging Standard for AI Agents
Your security team needs to review an AI agent before it goes to production. They clone the repo, trace API calls through source code, and spend two days trying to understand what it touches and why. There is no manifest. No declared capability set. No standard artifact to inspect.
Your ops team just received an agent from a vendor. They have no standard way to ask what it does before running it.
A third-party developer finished building an agent for you and needs to deploy it in your environment. You have no way to verify it does what they say it does, that it only touches the systems it’s supposed to touch, or that nothing changed between when they built it and when it arrived.
These are not edge cases. They are the current state of AI agent deployment. Agents are being pushed into production systems with real access to real data, yet there is no standard artifact that answers the most basic questions about what they are and what they do.
The .agent format exists to fix these use cases and more. The format specification and packaging pipeline are covered by a pending patent, and you can start using it today at https://github.com/nomoticai/agentpk
Introducing the .agent format
An .agent file is a self-contained archive with four components.
A manifest. A machine-readable declaration of what the agent is: name, version, runtime, entry point, dependencies, capabilities, and permissions. What tools does it use? What can it read? What can it write? What external services does it call? The manifest is structured, versioned, and inspectable by anyone before the agent runs. It is the answer to every basic question a receiving system should be asking.
A cryptographic integrity binding. A SHA-256 hash over the manifest content, computed at packaging time and embedded in the archive. If anything changes after packaging, validation fails for any byte in any file. The receiving system knows immediately what it received is not what was certified. This closes the gap between the reviewed and deployed versions.
A behavioral trust score. Before packaging, the agent can be run through a multi-level analysis pipeline that compares the manifest’s declarations with the source code’s behavior. The pipeline has four levels: structural validation, static code analysis, LLM semantic verification, and runtime sandbox observation. Each level that runs contributes to a score from 0 to 100. Each skipped level, due to Docker being unavailable or no LLM key being configured, subtracts from the score and documents the reason. The score and the full analysis record are embedded in the package before the integrity hash is finalized.
Ed25519 package signing. Packages can be signed with an Ed25519 private key, producing a portable .sig file containing the manifest hash, signature, algorithm identifier, and optional signer metadata. Ed25519 is the current standard used by SSH, Signal, Let’s Encrypt, and Git. It produces small keys and 64-byte signatures that travel alongside the package. Recipients verify with the corresponding public key before deployment. If anything in the package changed after signing, verification fails.
agent keygen --out my-key.pem
# Produces my-key.pem (private, ~119 bytes) and my-key.pub.pem (public)
agent sign fraud-detection-1.0.0.agent --key my-key.pem --signer "Acme AI"
# Produces fraud-detection-1.0.0.agent.sig
agent verify fraud-detection-1.0.0.agent --key my-key.pub.pem
# ✓ Signature valid
The result is a package you can hand to an ops team, a compliance reviewer, a CI/CD pipeline, or a governance platform, and they can answer basic questions about it without running it first.
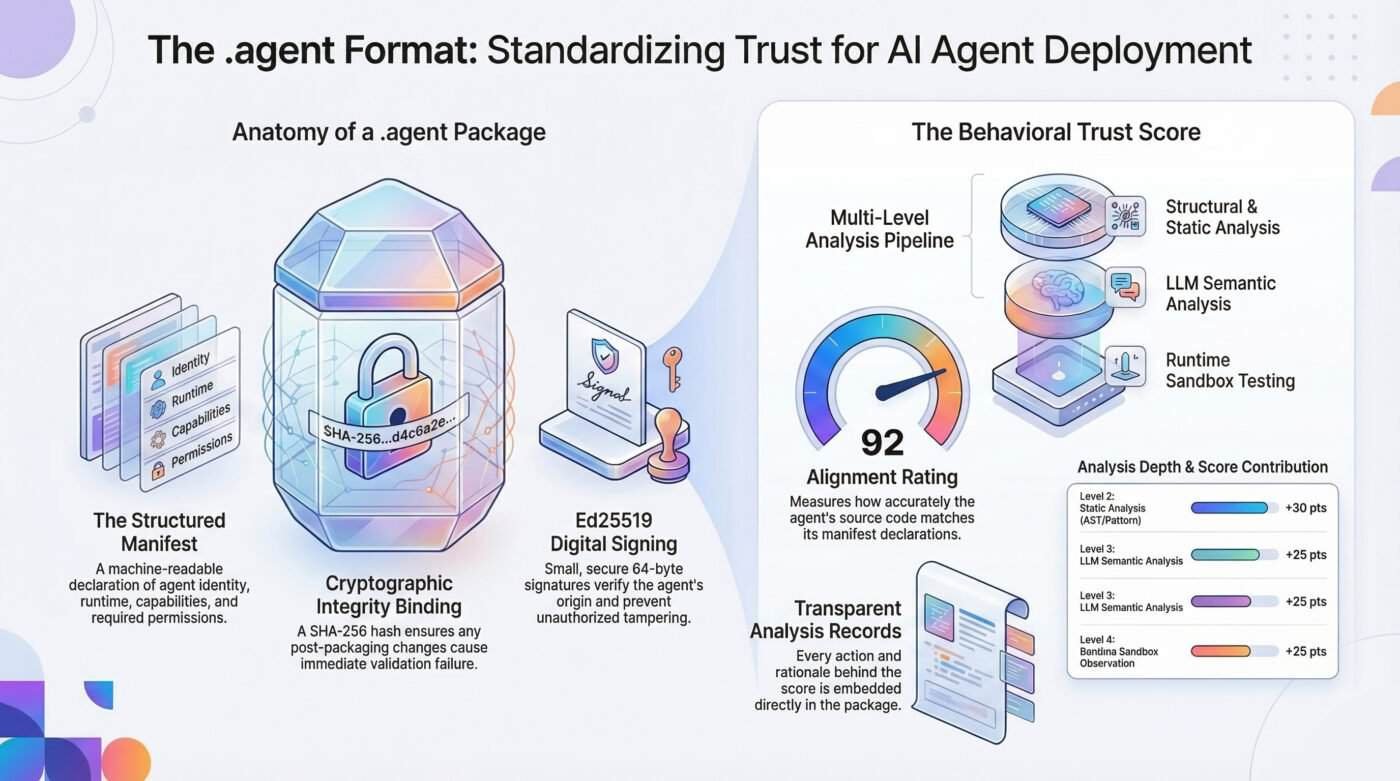
What the trust score actually means
Clarity matters here. The score does not guarantee safety. An agent with a 94 rating is not certified as harmless.
Instead, the score reflects an agent analyzed across multiple layers. Its source code matched against its manifest. Its runtime behavior is observed in a sandbox. Each check is completed with documented evidence embedded directly in the package.
An agent with a score of 12 sits in a different category. It may have been packaged without proper analysis. Static review may have uncovered capabilities not declared in the manifest. Sandbox testing may have revealed outbound network calls to unknown hosts.
The score does not conceal these findings. It brings them forward. The analysis record is stored in the package and can be reviewed before deployment. Every action, discovery, and rationale behind the score is visible.
Today, the gap between examined and unexamined agents remains invisible. Both appear identical. Both deploy the same way. The .agent format changes that by making the difference visible, durable, and portable.
Multi-language, open spec
The format is language-agnostic. A Python agent, a Node.js agent, a Go binary, a Java service. They all pack identically. The manifest declares the runtime. The integrity hash covers everything. The analysis pipeline uses language-specific extractors: full AST analysis for Python, Node.js, and TypeScript; pattern-based signal extraction for Go and Java. If a language does not have an extractor yet, the level is skipped, and the reason is logged in the analysis record.
pip install agentpk
agent init my-agent --runtime nodejs # scaffold for any runtime
agent pack ./my-agent --analyze # pack with behavioral analysis
agent inspect my-agent-1.0.0.agent # inspect before deploying
agent serve # REST API and browser UI
The agent serve command starts a local REST API and a packaging UI. Drag in a directory, configure analysis options, and download a certified .agent file without touching a terminal. This matters for teams where not everyone deploying agents is comfortable at the command line.
The spec is public and licensed under CC BY 4.0. The tooling is MIT licensed. The goal is for .agent to be a standard portable, self-describing, verifiable unit of deployment that any tool in the ecosystem can read, inspect, and reason about before it runs.
Where it fits in the governance stack
The .agent format is the packaging layer. It does not evaluate agent behavior during execution, enforce permissions mid-action, or provide runtime governance. Those are separate problems that require separate infrastructure.
What it provides is the foundation on which everything upstream depends. A runtime governance system evaluating an agent’s behavior is more effective when it can verify, from a signed manifest, what that agent was declared capable of. A compliance review is more tractable when the capability set is explicit rather than inferred from code. An audit trail is more meaningful when the agent version deployed matches, provably, the version reviewed and signed.
Agents are getting more capable and more consequential faster than the tooling around them is maturing. The packaging layer is where the maturity gap is most visible and most fixable. Every other software ecosystem solved this problem. AI agents are the exception.
They should not be.
If you find this content valuable, please share it with your network.
Follow me for daily insights.
Book me to speak at your next event.
Chris Hood is an AI strategist and author of the #1 Amazon Best Seller Infailible and Customer Transformation, and has been recognized as one of the Top 30 Global Gurus for Customer Experience. His latest book, Unmapping Customer Journeys, will be published in 2026.