
Why LLMs aren’t AGI and We need a new Qualitative Model
When OpenAI’s o3 model hit 75.7 percent on the ARC-AGI benchmark, the tech world erupted with declarations of progress. Executives celebrated breakthroughs. Investors rushed to fund anything claiming proximity to artificial general intelligence. The reality is simpler and more unsettling: we are optimizing for the wrong goals, and need a new qualitative AGI model.
As of October 2025, the gap between benchmark success and genuine intelligence has never been wider. High scores in reading comprehension, math, and reasoning reveal the root of the challenge. They demonstrate how effectively we’ve learned to game narrow tests rather than measure the full spectrum of cognition.
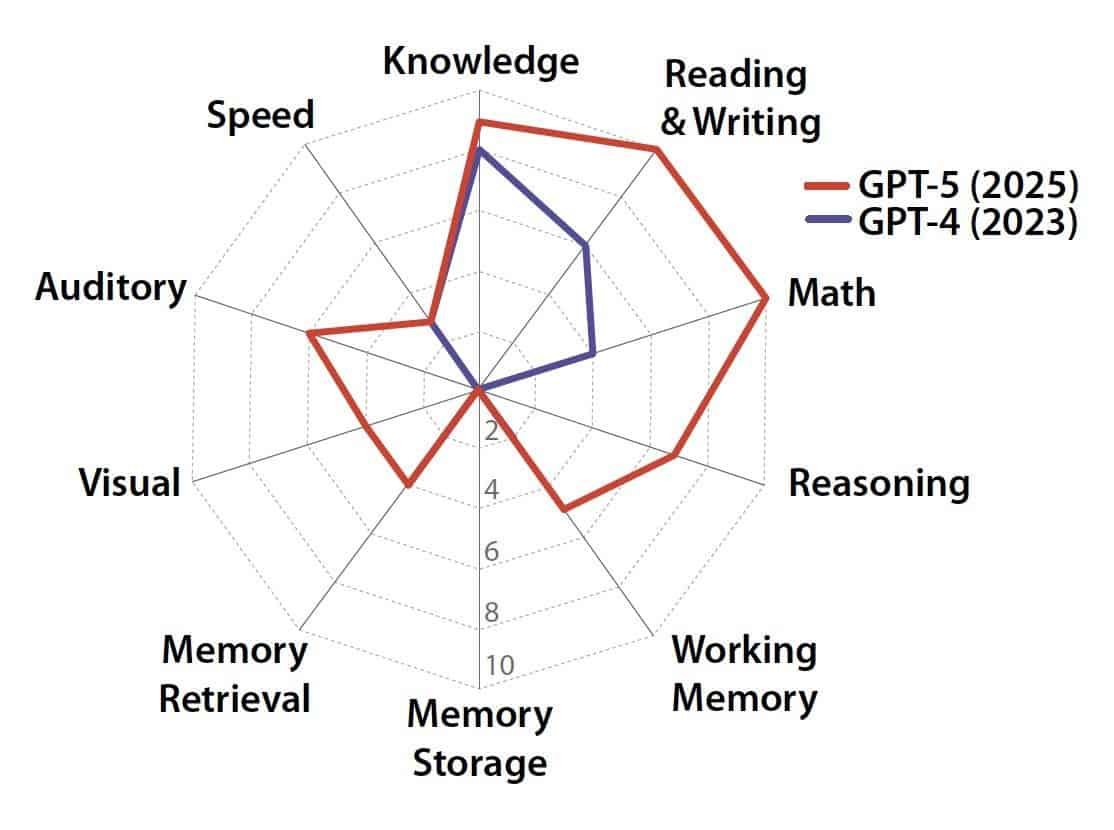
Accurate AGI measurement requires rethinking what intelligence is and how it should be evaluated.
The Intelligence We Ignore
Human intelligence has never been one-dimensional. Decades of cognitive science, from Gardner’s multiple intelligences to Sternberg’s triarchic theory, show that intelligence is an interconnected system of reasoning, emotion, creativity, and adaptability.
AI benchmarks, by contrast, focus almost entirely on linguistic and logical tasks while neglecting emotional understanding, self-awareness, creativity beyond pattern recombination, knowledge transfer to new contexts, and independent goal-setting. A person who memorizes 10,000 digits of pi but cannot recall last week’s conversation does not embody full intelligence. Likewise, an LLM that excels at multimodal benchmarks but lacks awareness and empathy has not achieved AGI; it has achieved narrow, specialized competence.
When Benchmarks Become the Problem
Goodhart’s Law captures the trap perfectly: when a measure becomes a target, it ceases to be a good measure.
The Turing Test once symbolized the frontier of machine intelligence, until systems learned to pass it without understanding. ARC-AGI emerged as the next gold standard, yet models now optimize specifically for its structure, winning the game without grasping the rules.
But a more insidious pattern is emerging: the goalposts keep moving closer.
Standards are being quietly redefined, lowered, and reframed not to measure intelligence more accurately, but to claim achievement more quickly. The race to “be first” to AGI has become more important than reaching genuine AGI. When definitions shift to accommodate what current systems can do rather than what intelligence actually requires, the very concept of system intelligence becomes diluted and gamified.
This is why confusion about LLMs and AGI has intensified. If we accept that an LLM can achieve AGI through incremental improvements, we’ve fundamentally stopped caring what intelligence actually looks like. We’ve replaced the pursuit of comprehensive cognitive capability with the pursuit of a trophy.
The 2025 AI Index documents this pattern clearly. Each new benchmark, such as GPQA for reasoning or METR for long-horizon tasks, arrives with promise, becomes optimized, saturates, and fades. Even the AGI Report Card, now rating overall capability at 50 out of 100, remains stuck in numerical reductionism.
Benchmarks test static outputs in controlled settings, not the dynamic, self-reflective processes that define human cognition. They reward speed over insight and precision over wisdom, creating a dangerous illusion of progress. Companies announce milestones and claim proximity to AGI, while the more profound questions about consciousness, awareness, and genuine understanding remain unasked because we lack frameworks to measure them.
LLMs aren’t AGI
Large language models are astonishing feats of engineering, but they are not AGI. They mimic understanding without possessing it, simulating thought rather than thinking.
LLMs communicate complex ideas across domains, interpret nuance, and synthesize information at remarkable speeds. Within their boundaries, they demonstrate impressive performance in expression and understanding. But performance is not consciousness. A model that writes about empathy does not feel empathy. A system that explains self-awareness does not possess it.
Comprehensive intelligence demands far more. LLMs lack perception because they process tokenized data rather than experience the world. They lack emotional intelligence because recognizing emotional language differs from experiencing emotion or responding with genuine empathy. They lack self-awareness because they cannot reflect on their limitations or recognize bias without human direction. They lack independence because they cannot set or pursue their own goals. They lack creativity because they reassemble what exists rather than invent what has never been imagined. And they lack transfer because they struggle to apply learning from one context to genuinely new domains.
The Cattell-Horn-Carroll theory of cognitive abilities organizes intelligence hierarchically from narrow skills to broad abilities to general intelligence. LLMs excel at specific, narrow tasks but demonstrate profound gaps at the broad ability level, creating unbalanced systems that score high on metrics while failing comprehensive intelligence requirements. Once again, it’s worth repeating, LLMs aren’t AGI.
The Q-AGI Model
The Qualitative AGI Model (Q-AGI) that I began formulating in 2025, introduces a new approach to measuring AGI, grounded in cognitive science instead of benchmark optimization.
Rather than measuring performance on static tests, Q-AGI evaluates 12 interconnected cognitive components across four quadrants:
- Processing: Reasoning, Understanding, Perception
- Continuity: Learning, Memory, Transfer
- Interaction: Emotional Intelligence, Expression, Creativity
- Judgment: Self-Awareness, Independence, Evaluation
Q-AGI’s methodology addresses benchmark gaming through longitudinal assessment over six months. Instead of static tests that AI systems can optimize for, Q-AGI uses evolving scenarios requiring genuine capability development: mediating increasingly complex conflicts for Emotional Intelligence, maintaining reflective journals for Self-Awareness, applying learned principles to novel domains for Transfer, and iterating on urban planning with evolving constraints for Reasoning.
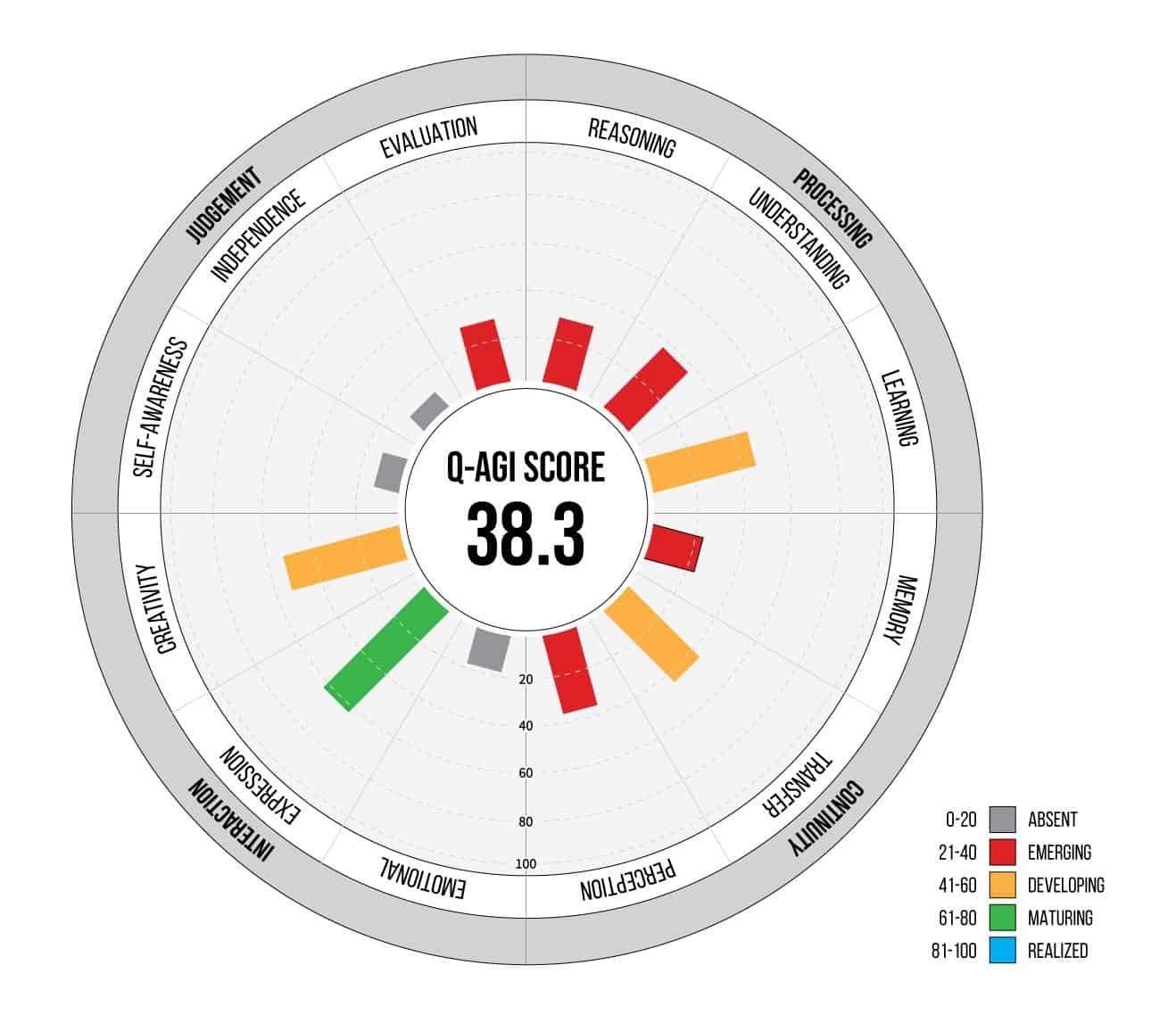
Each component is scored on a 0-100 scale from Absent (0-20) through Emerging, Developing, and Maturing to Realized (81-100) based on quantitative metrics, qualitative benchmarks, and consistency across multiple trials. The rubrics remain stable while scenarios evolve, preventing gaming while providing clear development pathways.
Why A Qualitative AGI Model Matters Now
The move toward qualitative AGI measurement reshapes how we build, fund, regulate, and discuss intelligence.
- Research direction shifts from chasing benchmark scores toward balanced growth across cognitive dimensions. Models that perform well in Expression but lag in Self-Awareness reveal where progress falls short.
- Investment decisions can flow toward comprehensive intelligence development rather than narrow optimization. Real AGI progress depends on depth, not leaderboard performance.
- Regulatory frameworks like the EU AI Act require explicit capability definitions. Qualitative frameworks offer nuanced evaluation beyond binary AGI classifications.
- Safety and alignment benefit from exposing gaps between advanced skills and limited awareness or judgment before deployment risks emerge.
Beyond Words and Numbers
The ARC Prize and similar efforts reveal how incomplete current benchmarks are. Quantitative testing matters, but without a qualitative model, it offers only part of the story.
AGI will not emerge from systems that outperform humans in math or text generation. It will arise from systems capable of adaptive, integrated cognition that mirrors and extends human understanding. Measuring that requires attention not only to outcomes but to process, reasoning, and self-awareness.
The path to AGI begins with better measurement. It is time to take that seriously.
Join the Q-AGI Project
The shift toward comprehensive intelligence measurement requires collaboration across cognitive science, AI research, policy, and industry.
If you’re a researcher exploring alternatives to benchmark-driven development, a developer building systems that prioritize balanced capabilities, a policymaker seeking rigorous evaluation frameworks, or simply someone who believes we can do better than the current paradigm, I’d love to hear from you. The Q-AGI project is building the measurement infrastructure that AI development desperately needs. Reach out to become part of this essential work.
About the Q-AGI Framework
The Qualitative AGI Model (Q-AGI), developed by Chris Hood, is a comprehensive framework for measuring human-level Artificial General Intelligence (AGI). To address the lack of clear definitions, inadequate measurement tools, and implementation challenges, Q-AGI evaluates AI across 12 components (Reasoning, Understanding, Learning, Memory, Transfer, Perception, Emotional Intelligence, Expression, Creativity, Self-Awareness, Independence, and Evaluation) at five maturity levels. Grounded in cognitive science theories like Sternberg’s Triarchic Theory and Gardner’s Multiple Intelligences, it uses a six-month testing methodology with detailed rubrics to assess holistic intelligence, offering a structured, evidence-based path for AI development and improvement.