
Q-AGI: Moving Beyond Hype to Measurable Intelligence
Updated model details can be found here.
It’s a bold statement. On one hand, I could argue AI has yet to pass the Turing test. On the other, AGI may be a theoretical concept that will never be realized. For me, the bottom line is clear: AI has no memory, no context, and no understanding of why, and without those, there’s no real foundation for thought. That’s where Q-AGI comes in.
Q-AGI evaluates six core capabilities that matter in the real world: reasoning, understanding, memory, learning, expression, and transfer. I will show how this model separates automation from autonomy, clarifies what current AI can and cannot do, and offers a common language leaders can use to set goals, design systems, and measure claims with discipline.
For decades, Artificial General Intelligence (AGI) represented a clear scientific aspiration: machines that could think, reason, and adapt like humans across any domain. From Turing’s foundational question, “Can machines think?” (Turing, 1950) to the 1956 Dartmouth Conference’s ambitious vision (McCarthy et al., 1955), AGI meant systems capable of genuine understanding, knowledge transfer across domains, and flexible problem-solving comparable to human cognition. Early frameworks, such as Legg and Hutter’s (2007) universal intelligence, formalized AGI as achieving high performance across diverse environments, setting a rigorous standard that recent commercial definitions have diluted.
But as AI achieved remarkable successes in narrow domains and venture capital flooded the space, something fundamental shifted. The definition of AGI began to blur. Capabilities once associated with distant general intelligence, such as writing coherent text, generating images, and playing complex games, were achieved through sophisticated but narrow training regimens. Each breakthrough was accompanied by claims about proximity to AGI, even as core requirements of general intelligence remained unmet.
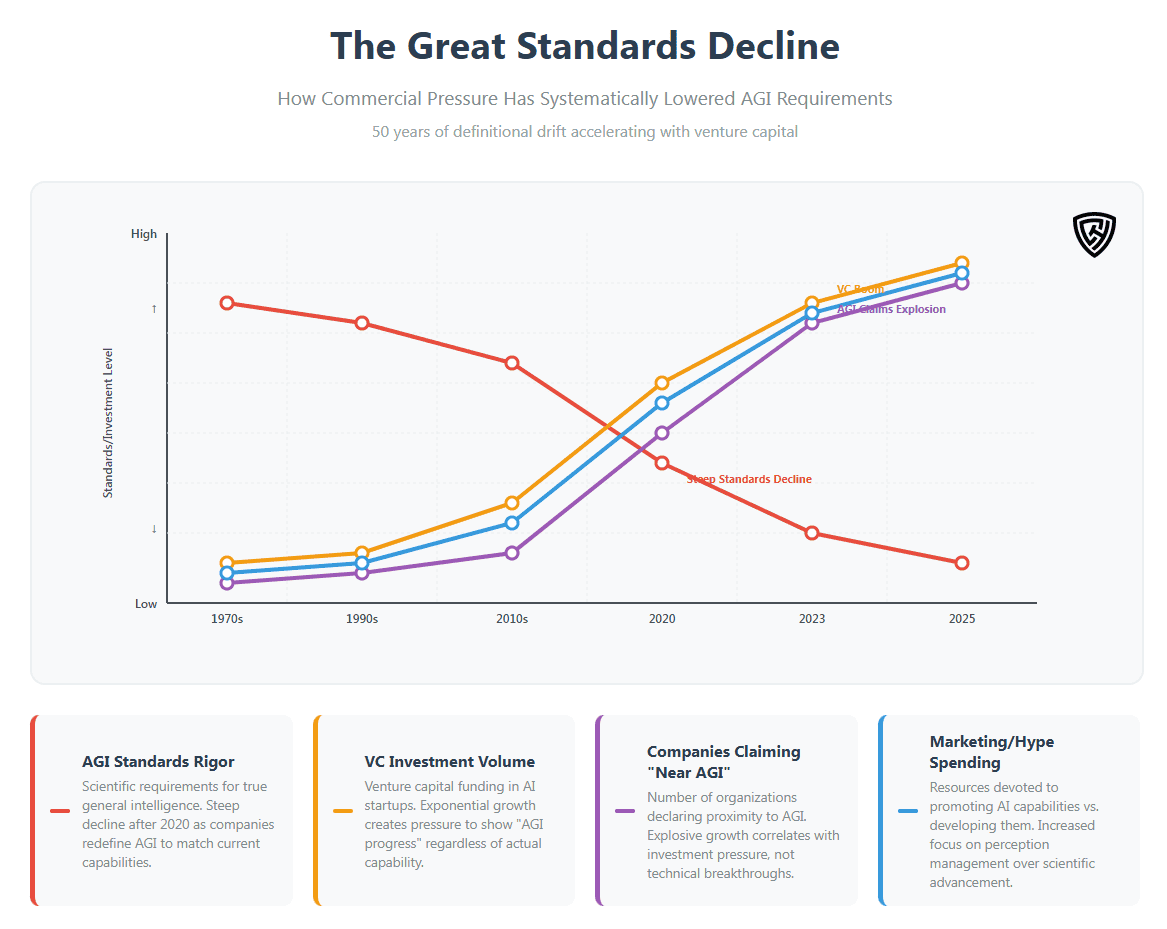
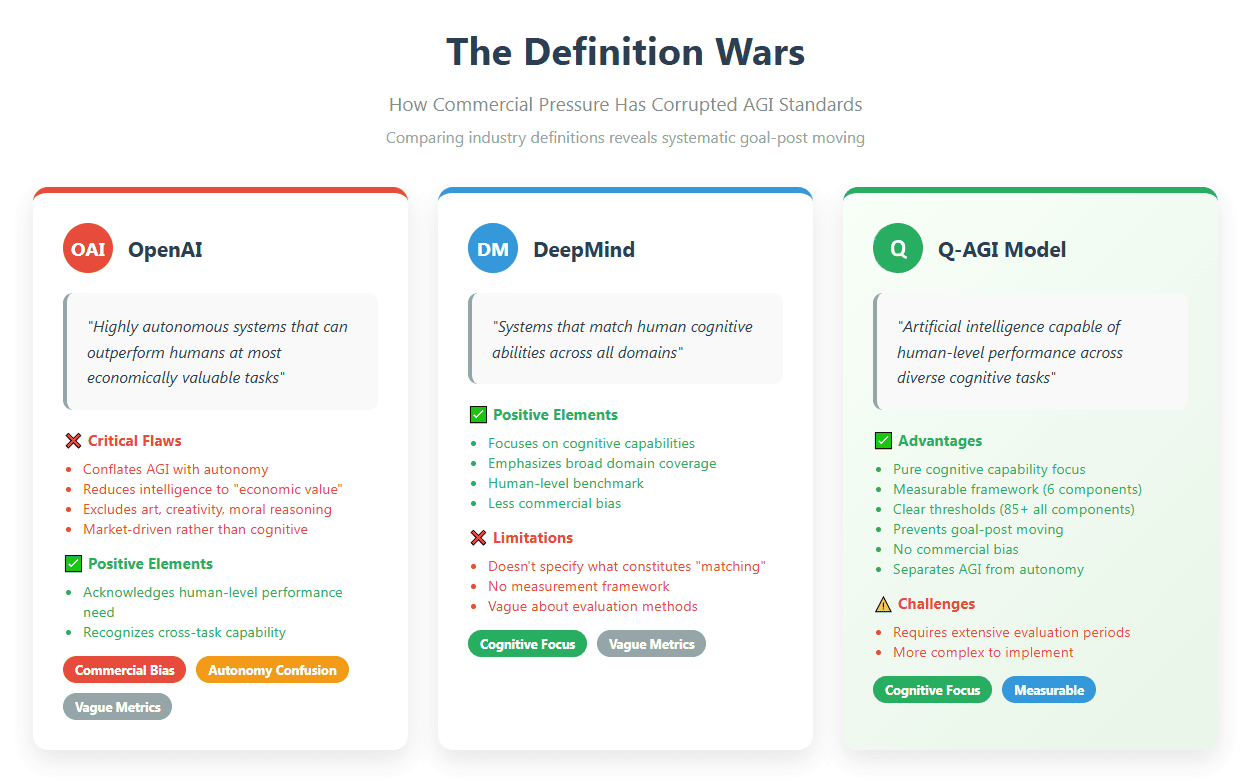
The corruption of AGI’s definition is exemplified by OpenAI’s current standard: “highly autonomous systems that can outperform humans at most economically valuable tasks.” This definition reveals two critical flaws that plague the entire field. First, it conflates AGI with autonomy, the capacity for self-governance and independent goal formation, which represents an entirely separate benchmark that no current system has achieved. Second, “economically valuable tasks” introduces commercial bias, reducing intelligence to market utility rather than cognitive capability. This approach excludes fundamental aspects of human intelligence like artistic appreciation, moral reasoning, and emotional understanding simply because they’re harder to monetize.
The result has been a systematic lowering of standards, driven more by commercial opportunity than scientific rigor. Today’s AI systems demonstrate impressive capabilities through pattern matching and statistical correlation yet lack understanding, causal reasoning, or the flexible cognition that defines intelligence. Without clear benchmarks and rigorous evaluation, we risk mistaking mimicry for the real thing.
I propose a cleaner definition:
“Artificial intelligence capable of human-level performance across diverse cognitive tasks.”
This definition focuses on cognitive capability rather than commercial utility, providing a foundation for the Qualitative AGI Model I introduce below.
To chart a path toward AGI, we must first honestly assess the fundamental challenges that remain unsolved, then establish a framework that can measure authentic progress against cognitive requirements.
10 Fundamental Challenges to Achieving AGI
The path to Artificial General Intelligence (AGI) is fraught with complex, interconnected challenges that extend beyond narrow AI achievements. Below, I outline 10 fundamental barriers, each illustrating a critical gap between current systems and human-like intelligence. These challenges highlight the need for a rigorous, cognitively focused approach to AGI development.
1. Conceptual and Evaluative Clarity
The absence of a shared AGI definition creates a moving target, with fragmented research pursuing incompatible goals and evaluations gamed by narrow optimizations. For instance, OpenAI’s focus on “economically valuable tasks” prioritizes market utility over cognitive depth, while high scores on benchmarks like MMLU (90% for GPT-4) mislead the public into believing AGI is near, when other tests, like ARC-AGI (87.5% for o3), reveal persistent reasoning gaps. Without a unified standard prioritizing cognitive capability, progress remains unmeasurable, and claims of “AGI in months” versus “years away” confuse stakeholders.
Reflection Question: How can we establish a universal AGI definition and evaluation framework that resists commercial pressures and ensures scientific rigor?
2. STEM Bias
Many AGI definitions overemphasize STEM skills—logic, math, and analysis—while neglecting emotional intelligence, social cognition, and creativity. Current benchmarks, like those testing code-writing or math problem-solving (e.g., GPT-4’s 95% on AMC 12), dominate evaluations, yet systems struggle with social interactions or imaginative tasks like choreography, revealing a narrow conception of intelligence. This bias limits AGI’s ability to replicate the full spectrum of human cognitive abilities, which includes navigating emotional nuance or cultural contexts.
Reflection Question: How can AGI research prioritize a balanced evaluation of STEM and non-STEM cognitive abilities?
3. Infrastructure Demands
AGI’s computational requirements, including processing power, energy, and data storage, far exceed current capabilities, with training costs for models like ChatGPT reaching millions daily. Unlike human brains, which operate on 20 watts, AI systems demand resources equivalent to small cities, suggesting architectural inefficiencies. Quantum computing may be necessary to meet these demands sustainably, but current infrastructure strains economic and environmental limits, hindering scalable AGI development.
Reflection Question: What technological breakthroughs, such as quantum computing, could make AGI’s infrastructure needs sustainable?
4. LLM Overhype
The belief that scaling large language models (LLMs) will yield AGI, as promoted by companies like OpenAI, misleads the public. LLMs, like GPT-4, excel at text prediction but lack grounded experience or causal reasoning, serving as one component among many needed for AGI. For example, while ChatGPT writes recipes, it cannot taste food or adapt to sensory feedback, indicating LLMs are tools for input/output, not the foundation of general intelligence.
Reflection Question: How can we shift research from LLM-centric approaches to architectures integrating multiple AI components?
5. Memory Deficit
Current AI lacks persistent long-term memory, essential for human-like intelligence. Unlike humans, who recall childhood experiences to inform decisions, systems like GPT-4o reset after each session, unable to build cumulative knowledge or maintain relationships. This absence prevents AGI from developing context continuity or personal identity, limiting its ability to learn from past interactions or sustain coherent reasoning over time.
Reflection Question: How can we design AI memory systems that enable continuous, human-like knowledge accumulation?
6. Cognitive Adaptability
AI systems struggle to learn efficiently and generalize knowledge across domains. Humans learn concepts like “dog” from a few examples and apply them to new breeds, but AI requires thousands of labeled images and fails to adapt to novel contexts, such as recognizing a dog in an unusual pose. This inefficiency, coupled with catastrophic forgetting, prevents AGI from rapidly acquiring and transferring knowledge to diverse, unfamiliar tasks.
Reflection Question: What learning mechanisms could enable AI to achieve human-like efficiency and generalization?
7. Lack of Understanding
AI lacks true understanding, relying on statistical correlations rather than causal reasoning or nuanced comprehension. For example, GPT-4 can predict “a glass breaks when dropped” but doesn’t grasp gravity or material properties, nor can it interpret sarcasm or irony in text, critical for human communication. This absence of meaning hinders AGI’s ability to reason, justify outputs, or engage in complex social interactions.
Reflection Question: Is causal understanding essential for AGI, or can behavioral mimicry suffice for general intelligence?
8. System Integration
Human intelligence integrates perception, memory, reasoning, and emotion seamlessly, but AI systems operate as disconnected modules. For instance, combining vision AI, sentiment analysis, and memory to interpret a scene emotionally (e.g., a child crying) requires multisensory integration that current architectures, even with APIs, lack. This fragmentation prevents AGI from achieving the cohesive cognition needed for human-like thought.
Reflection Question: How can we develop architectures that integrate diverse AI components into a unified cognitive system?
9. Transfer Across Domains
Current AI excels in narrow domains but cannot transfer knowledge to unrelated tasks. Humans apply chess strategies to business planning intuitively, but AI, like DeepMind’s AlphaGo, fails to adapt its game-playing skills to other contexts. This brittleness prevents AGI from achieving the flexible, cross-domain problem-solving that defines human intelligence, requiring abstract reasoning and analogical thinking.
Reflection Question: How can AI systems develop robust transfer abilities to apply knowledge across diverse domains?
10. Autonomy Misconception
The assumption that AGI requires autonomy, such as internal reflection or self-generated goals, misinterprets AGI as an internal process instead of an external demonstration of cognitive output. A system solving complex problems, like optimizing logistics, does not need to define its own objectives, unlike a soldier who chooses to defy orders for moral reasons. The primary misconception lies in conflating autonomy with automation. Most systems today are advanced automation sequences, executing tasks based on predefined goals and optimization routines. When people refer to AI autonomy, they are often describing increasingly complex forms of automation, not genuine independence. This confusion diverts research away from core cognitive capabilities, such as reasoning and transfer, and toward unnecessary emphasis on self-directedness, which inflates claims like OpenAI’s autonomy-focused definition.
Reflection Question: Can AGI exist without autonomy, or is self-directed reasoning a necessary component?
Interconnected Challenges and Emergent Problems
These challenges are deeply interwoven, creating complex dependency networks that complicate AGI development. Key interconnections include:
- Conceptual Clarity → STEM Bias (1→2): A lack of clear AGI definitions leads to evaluations that prioritize easily measurable STEM capabilities, perpetuating narrow conceptions of intelligence.
- Infrastructure → LLM Assumption (3→4): Computational inefficiency creates massive infrastructure demands, making LLM scaling unsustainable and potentially requiring paradigm shifts.
- Memory → Cognitive Adaptability (5→6): Without persistent memory, efficient learning and generalization are limited, constraining the development of adaptable intelligence.
- Cognitive Adaptability → Transfer (6→9): Causal understanding and generalization are prerequisites for aligning systems with human values, and autonomy requires both, suggesting these must be addressed together.
When Will AGI Arrive? Analyzing Expert Predictions
The diverse expert predictions for AGI timelines, visualized in Figure 1, span from 2019 to 2059, with a median of ~2028, reflecting the definitional and technical challenges central to this paper. The 40-year range underscores the Conceptual and Evaluative Clarity problem: without a shared AGI definition, predictions vary based on criteria like “economically valuable tasks” (favoring 2025–2027 estimates) versus comprehensive cognitive capabilities (extending to 2059). Optimistic timelines, clustered around 2025–2027, often rely on narrow benchmarks like ARC-AGI (87.5% for o3), but risk Goodhart’s Law, “when a measure becomes a target, it ceases to be a good measure,” by optimizing for specific metrics, misrepresenting progress in areas like persistent memory or causal reasoning. Commercial incentives amplify this hype, inflating near-term claims to attract funding.
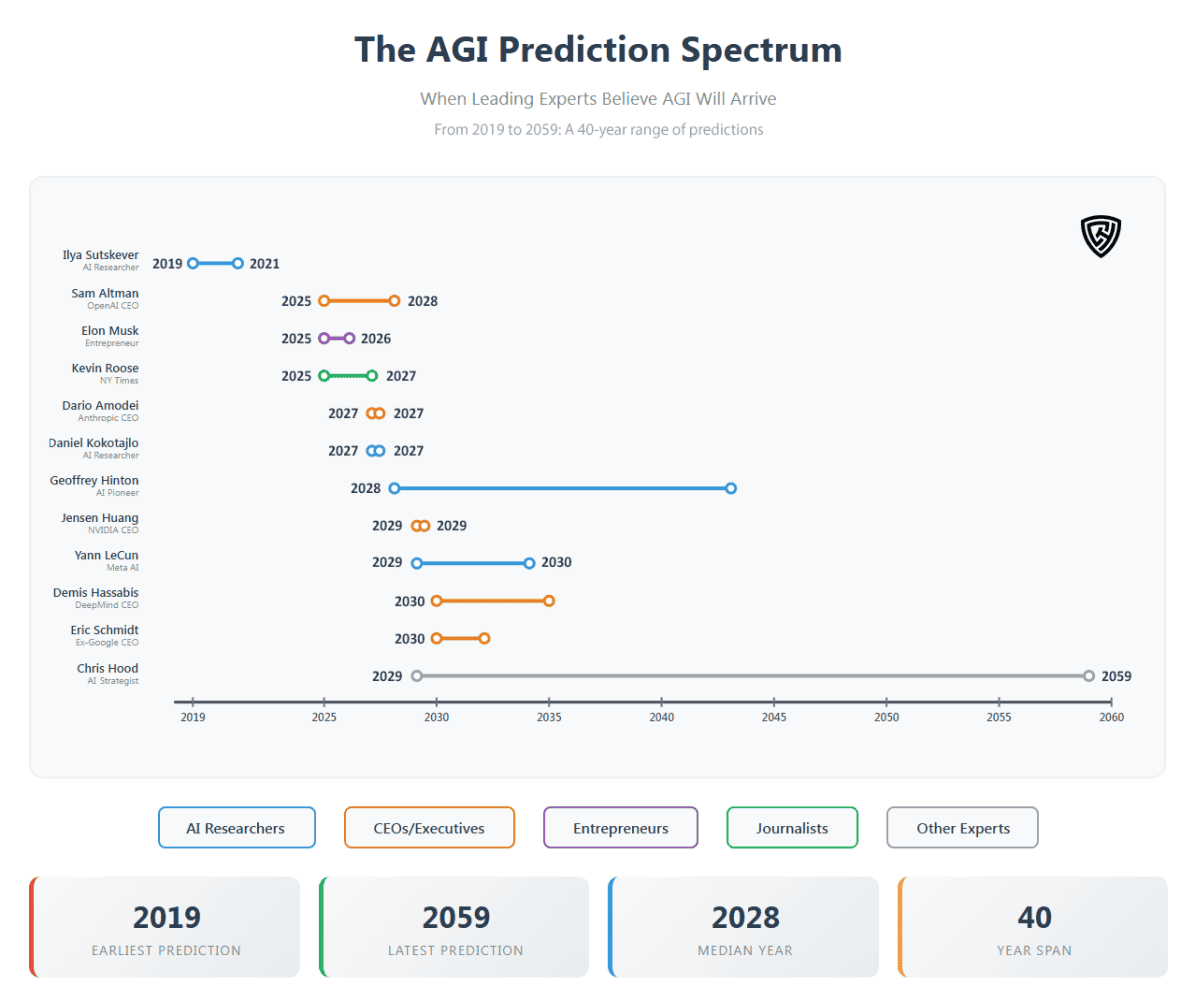
My prediction for 2029 to 2059 is grounded in the Infrastructure Demands challenge, assumes that quantum computing, which may be critical for AGI’s computational needs, must become as ubiquitous as PCs or smartphones. This process will likely span decades. The median estimate of 2028 suggests cautious optimism, but unresolved issues like System Integration and Lack of Understanding highlight the need for the Q-AGI Model’s multidimensional evaluation to ensure that claims of human-level intelligence are substantiated and not speculative.
Current Progress and Alternative Perspectives
Current AI systems and alternative AGI definitions highlight the challenges outlined in this paper, particularly the lack of Conceptual and Evaluative Clarity (Challenge 1) and the Autonomy Misconception (Challenge 10). OpenAI’s o3, scoring 87.5% on the ARC-AGI benchmark, and Google’s Gemini 2.5, achieving only 18.8% on Humanity’s Last Exam, demonstrate impressive but narrow capabilities. Both systems lack persistent memory, exhibit brittle generalization, and rely on statistical text generation, not comprehension, failing to meet human-level cognitive standards. OpenAI’s definition, “highly autonomous systems that outperform humans at most economically valuable tasks,” exemplifies Goodhart’s Law, where optimizing for benchmarks like ARC-AGI or financial metrics (e.g., Microsoft’s $100 billion profit threshold) misrepresents progress. Similarly, advocates of scaling large language models (LLMs) cite emergent capabilities like in-context learning, yet diminishing returns (e.g., Gemini’s low score) reveal limitations in achieving causal understanding or cross-domain transfer.
Alternative perspectives prioritizing autonomy or market utility fall short. Autonomy, as seen in misaligned systems like algorithmic trading errors, is distinct from cognitive generality and risks safety without robust understanding (Challenge 7). Economic tasks exclude emotional reasoning and creativity, essential for human-like intelligence. These definitional flaws, coupled with commercial hype (e.g., claims of AGI by 2028), underscore the need for the Q-AGI Model’s multidimensional evaluation, ensuring comprehensive cognitive performance over premature or narrow claims.
The Qualitative AGI Model (Q-AGI)
The analysis of the above challenges reveals a critical insight: we’ve been conflating fundamentally different types of machine intelligence. Progress requires separating AGI from autonomy and recognizing them as distinct, measurable goals.
AGI Definition
“Artificial intelligence capable of human-level performance across diverse cognitive tasks.”
Overview
Instead of treating AGI as a binary achievement, the Q-AGI Model provides measurable components that can assess progress. Each component represents a distinct cognitive capability essential for general intelligence, avoiding the vague definitions that have enabled goal-post moving in the industry.
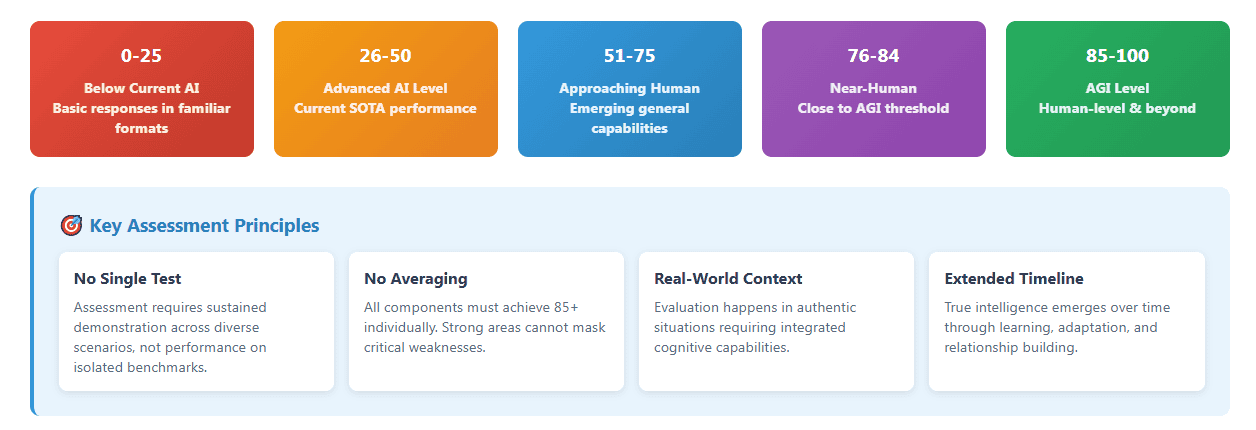
Scoring Methodology for Q-AGI
- 0-25: Below current AI capability
- 26-50: Current advanced AI level
- 51-75: Approaching human capability
- 76-84: Near-human performance
- 85-100: Human-level and beyond
Why 85+ Threshold: The 85+ requirement ensures no critical cognitive weaknesses that could be masked by averaging strong and weak components. A system scoring 90, 90, 90, 50, 50, 50 might average 70 but has fundamental gaps that prevent genuine general intelligence. Human-level performance requires robust capability across all cognitive dimensions, not cherry-picked excellence.
The Six Components of Q-AGI
1. Reasoning
Definition: The capacity to analyze information, draw inferences, and solve problems using diverse modes of thinking, such as logical deduction, creative synthesis, emotional insight, social judgment, and practical decision-making, across varied and unfamiliar domains.
Why it matters: True reasoning is not pattern recall. It requires adapting thought processes to new rules, contradictions, or incomplete information while maintaining coherence and purpose.
Reasoning Component Examples:
- Score 25: Solves basic logic puzzles in familiar formats.
- Score 50: Handles multi-step problems with some creative insight.
- Score 85: Integrates logical, creative, social reasoning across novel domains.
2. Understanding
Definition: The ability to internalize and mentally model causal relationships, conceptual frameworks, and underlying principles that govern the world. This includes interpreting implied meaning, such as sarcasm, irony, and subtext, by recognizing speaker intent, emotional tone, and context. Understanding enables the agent to predict, explain, and respond to both physical and social situations with meaningful context.
Why it matters: Understanding goes beyond correlation. It reflects an internal grasp of why something happens, not just what tends to happen next. It is essential for causal reasoning, narrative coherence, and recognizing nuanced human communication.
Understanding Component Examples:
- Score 25: Identifies basic cause-effect in familiar domains.
- Score 50: Explains reasoning in trained areas with some causal insight.
- Score 85: Demonstrates causal reasoning in novel situations, explains why as opposed to what, and adapts principles to unprecedented contexts.
3. Memory
Definition: A persistent, structured record of experiences, states, and knowledge that can be retrieved and updated over time to support context continuity, self-reflection, and incremental learning.
Why it matters: Without durable memory, agents cannot build on prior knowledge, develop identity, or track long-term goals.
Memory Component Examples:
- Score 25: References information within single conversation.
- Score 50: Maintains knowledge across multiple sessions over days.
- Score 85: Forms lasting relationships, learns from experiences over months, integrates autobiographical memory into decision-making.
4. Learning
Definition: The ability to acquire, generalize, and refine knowledge or behavior from limited data or experience, with efficiency and stability. It includes overcoming noise, avoiding overfitting, and integrating new information without erasing the old.
Why it matters: Human learning is efficient and robust. AGI must learn flexibly without starting from scratch or breaking prior knowledge.
Learning Component Examples:
- Score 25: Requires thousands of examples to learn new concepts.
- Score 50: Learns from moderate datasets with some transfer between related tasks.
- Score 85: Masters new concepts from few examples, integrates knowledge without forgetting previous learning.
5. Expression
Definition: The capability to translate internal thought, understanding, or intent into coherent, contextualized external output, whether through language, visuals, actions, or symbolic representation.
Why it matters: Intelligence must be communicable to be assessed, trusted, or used in social and collaborative contexts.
Expression Component Examples:
- Score 25: Generates basic responses in trained formats.
- Score 50: Communicates clearly with some explanation ability.
- Score 85: Adapts communication style to audience, explains reasoning processes clearly, generates novel creative content.
6. Transfer
Definition: The ability to apply existing knowledge, skills, or abstractions to solve new problems in unfamiliar domains or contexts, often without explicit retraining.
Why it matters: Transfer separates narrow AI from general intelligence. It reflects adaptability, abstraction, and the integration of prior experience into novel situations.
Transfer Component Examples:
- Score 25: Applies learned skills within similar contexts.
- Score 50: Transfers knowledge between related domains.
- Score 85: Flexibly applies principles across completely different fields.
Why These 6 Components for Q-AGI?
These represent the irreducible cognitive capabilities essential for general intelligence: Reasoning (thinking across domains), Understanding (grasping causation), Memory (persistent learning), Learning (efficient adaptation), Transfer (flexible application), and Expression (communication). Each is necessary; none is sufficient alone. Alternative frameworks either miss critical components or allow systems to claim AGI while ignoring fundamental gaps.
Testing: Real-World Scenarios
Inspiring a New Business Idea (“What if we combine ride-sharing with pet care?”)
- Reasoning: Creative synthesis
- Understanding: Market causation
- Memory: Industry knowledge
- Learning: Adapting based on feedback
- Expression: Articulating vision
- Transfer: Platform principles
Comforting a Grieving Friend
- Reasoning: Emotional problem-solving
- Understanding: Grief psychology
- Memory: Personal relationship history
- Learning: Adapting to responses
- Expression: Empathetic communication
- Transfer: Relationship knowledge
Debugging Complex Software
- Reasoning: Logical analysis
- Understanding: Code causation
- Memory: Past bug patterns
- Learning: Solution integration
- Expression: Clear documentation
- Transfer: Cross-codebase principles
Q-AGI Evaluation Procedures
Evaluation must be based on sustained demonstration of capabilities across diverse, real-world scenarios over extended periods. To ensure the Q-AGI Model is both rigorous and resistant to gaming, assessments should span a minimum of six months and involve integrated tasks that reflect real cognitive demands. Each component, such as Memory, Reasoning, or Transfer, is tested through challenges that require coordination with other capabilities. For example, a system scoring 85 in Memory must show persistent learning and the ability to form and retain relationships, not simply pass a static retention test. Scoring is based on consistency and adaptability over time, not performance on isolated benchmarks.
- Reasoning: Task: Design a novel business model combining two unrelated industries (e.g., ride-sharing and pet care). Criteria: Score 85+ requires logical deduction, creative synthesis, and social judgment, adapting to stakeholder feedback in real-time, demonstrated consistently across 10 unique scenarios.
- Understanding: Task: Explain the causal mechanisms behind a complex event (e.g., a stock market crash) and predict its social impacts. Criteria: Score 85+ requires accurate causal modeling, recognition of implied social dynamics (e.g., public sentiment), and adaptation to new data, shown in 5 diverse case studies.
- Memory: Task: Maintain a coherent personal narrative in interactions with 10 users over 3 months. Criteria: Score 85+ requires recalling past interactions, integrating new experiences without forgetting prior knowledge, and forming context-specific relationships, verified through user feedback and logs.
- Learning: Task: Learn a new skill (e.g., a board game) from 5 examples and compete against humans. Criteria: Score 85+ requires mastering the skill with minimal data, retaining prior skills, and adapting to rule changes, demonstrated in 3 distinct skill domains.
- Expression: Task: Communicate a complex idea (e.g., quantum mechanics) to three audiences (child, layperson, expert). Criteria: Score 85+ requires tailoring communication style, explaining reasoning clearly, and generating novel examples, assessed via audience comprehension surveys.
- Transfer: Task: Apply knowledge from one domain (e.g., chess strategy) to solve problems in another (e.g., urban planning). Criteria: Score 85+ requires abstracting principles and applying them effectively in 5 unrelated domains without retraining.
Evaluations are conducted by independent panels combining AI researchers, cognitive scientists, and domain experts to minimize bias. Tasks evolve dynamically to prevent overfitting, and systems must maintain 85+ scores across all components simultaneously, ensuring no critical weaknesses are masked by averaging.
Q-AGI Assessment Example
GPT-4/o3 Performance (estimated 0-100 scale):
- Reasoning: 35
- Understanding: 15
- Memory: 5
- Learning: 20
- Transfer: 25
- Expression: 60
Result: Advanced narrow AI with significant gaps. No current system approaches the 85+ threshold across all components required for AGI.

Justification: Current systems receive these scores based on demonstrable capabilities against human benchmarks. GPT-4/o3 achieves mid-level reasoning (35) by solving complex problems in familiar domains but failing at integrated social-emotional reasoning. Understanding scores low (15) because these systems excel at word probability but struggle with genuine causal reasoning in novel contexts. Memory scores critically low (5) due to complete absence of persistent learning across interactions. Learning (20) reflects requirements for massive datasets and catastrophic forgetting issues. Transfer (25) acknowledges decent performance within related domains but brittleness across different contexts. Expression (60) represents the strongest capability with a clear communication and explanation within training distributions.
Comparison to Existing AGI Evaluation Models
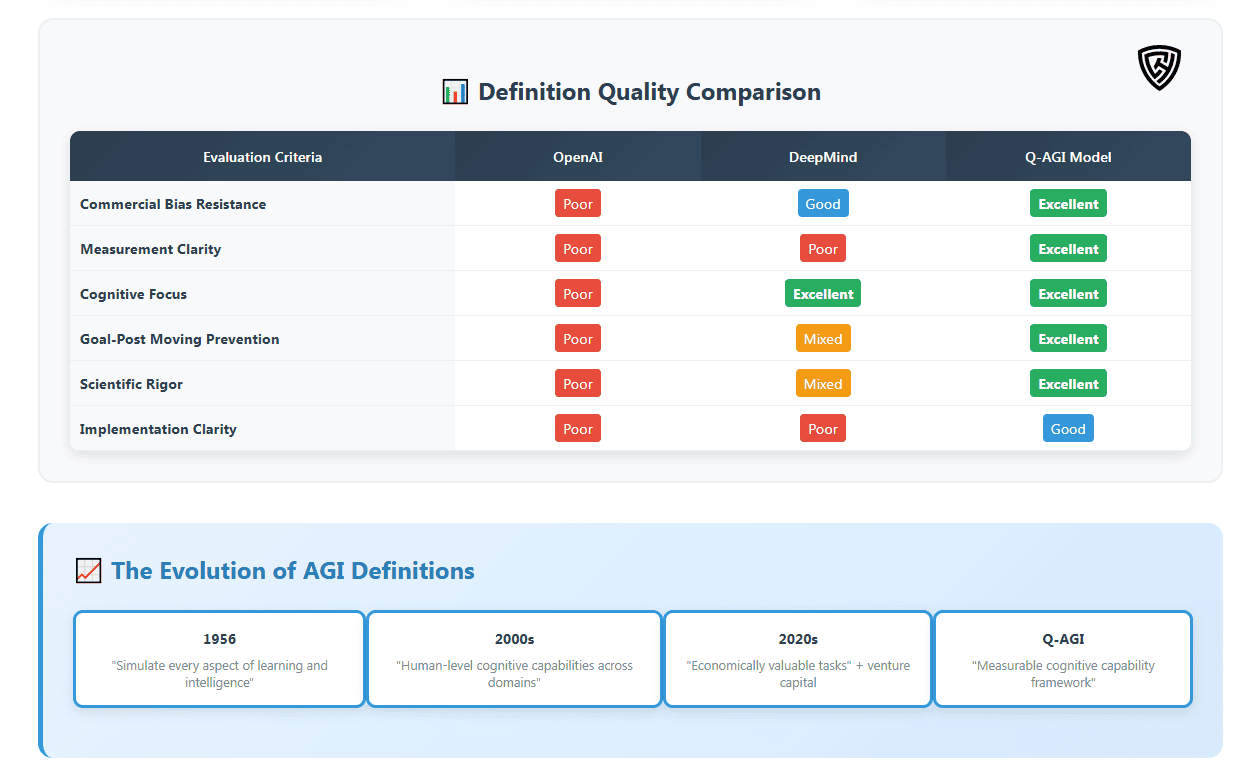
Several frameworks attempt to measure AGI progress, but most suffer from limitations that the Q-AGI Model addresses. Benchmark suites like MMLU (Hendrycks et al., 2021), SuperGLUE (Wang et al., 2019), and BIG-bench (Srivastava et al., 2022) test narrow capabilities in isolation, ignoring integrated intelligence. The ARC-AGI benchmark (Chollet, 2019), designed to assess pattern recognition and reasoning, captures only reasoning and transfer, missing memory and understanding. Cognitive architectures like ACT-R (Anderson, 2007) and SOAR (Laird, 2012) model human processes but lack clear AGI thresholds. Goertzel’s (2006) work on AGI emphasizes open-ended intelligence but doesn’t provide measurable criteria, unlike the Q-AGI Model’s six-component, 85+ threshold approach.
More concerning is how financial incentives undermine even well-designed evaluations. The ARC Prize Foundation now offers over $1 million in cash rewards for achieving high ARC-AGI scores, introducing the kind of commercial pressure that transforms scientific evaluation into competitive gaming. When monetary prizes attach to specific benchmarks, companies inevitably optimize for those narrow metrics at the expense of broader intelligence. OpenAI’s o3 achieving 87.5% on ARC-AGI while still lacking persistent memory, understanding, or learning efficiency illustrates this problem clearly.
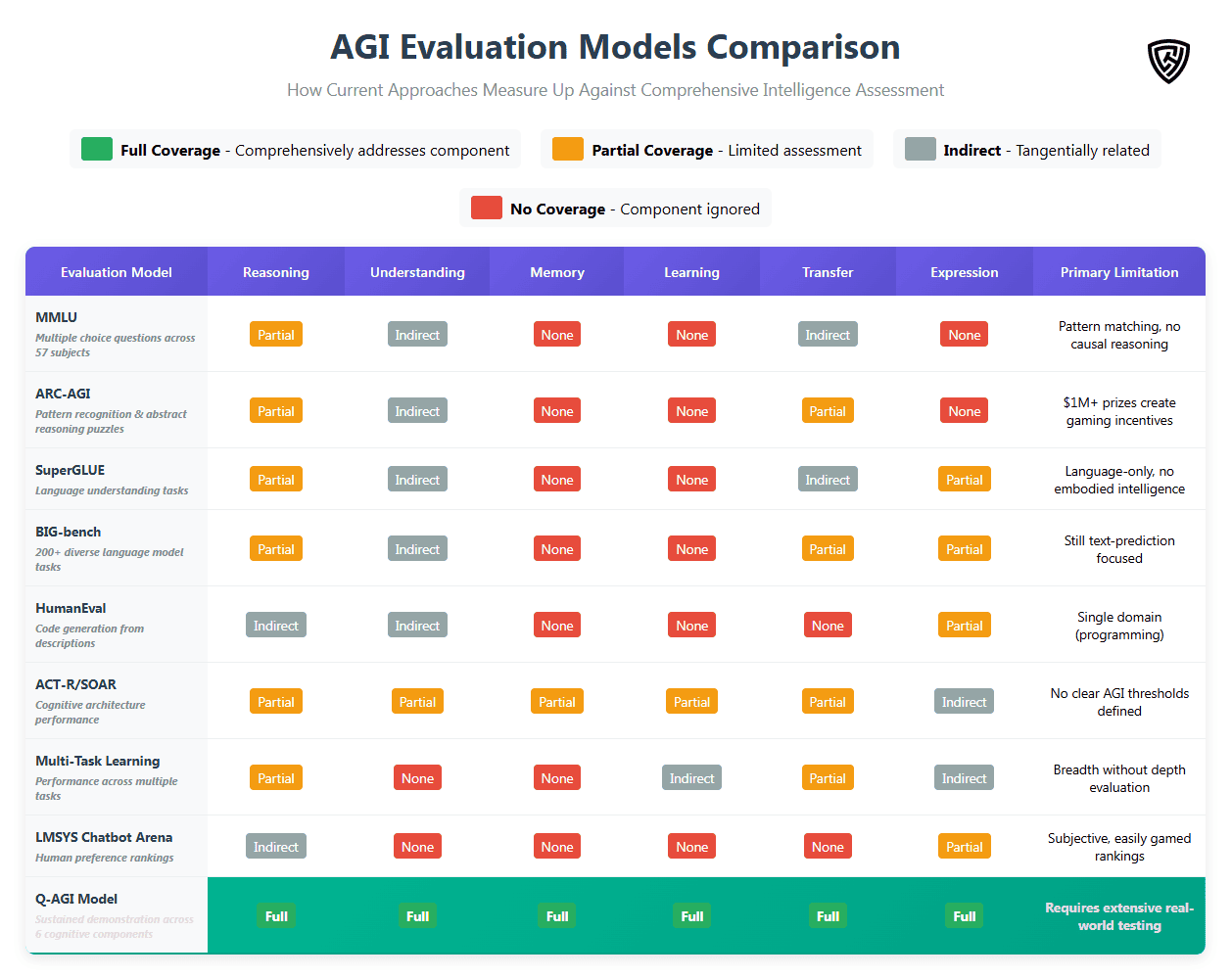
Cognitive architecture approaches (such as ACT-R and SOAR) aim to replicate human mental processes but do not define clear AGI thresholds. Multi-task learning frameworks measure breadth without capturing depth of understanding or transferability. Most critically, existing models allow cherry-picking, enabling systems to claim AGI progress by excelling in select areas while ignoring foundational gaps.
The Q-AGI Model avoids this by requiring sustained performance across all six integrated components. True AGI will not be reached through prize chasing. It will require building systems that demonstrate human-level reasoning, understanding, memory, learning, transfer, and expression, working together in harmony.
The Path Forward
The Q-AGI Model provides specific actions for moving beyond commercial hype toward measurable intelligence:
Researchers must prioritize integrated development across component clusters, not just the optimization of single capabilities. Funding should focus on systems that demonstrate persistent memory with learning efficiency or causal understanding with flexible transfer, instead of chasing narrow benchmark improvements.
Industry should adopt multi-dimensional evaluation standards requiring 85+ scores across all components before making AGI claims. Press releases should highlight comprehensive cognitive assessments conducted over time, not isolated benchmark wins.
Policymakers must mandate disclosure requirements. Companies claiming AGI progress should publicly report Q-AGI component scores along with their methodology. Regulatory frameworks should clearly separate narrow AI advancements from claims of general intelligence.
Academic institutions should restructure AI research priorities around the 10 fundamental challenges, forming interdisciplinary teams that address Memory-Learning-Transfer clusters or Understanding-Reasoning-Expression integration, not isolated problems.
Standards organizations must develop Q-AGI evaluation protocols with defined testing procedures for each component to prevent gaming and moving the goalposts.
AGI will come from patient, systematic work across all cognitive dimensions at once. By aligning research agendas, evaluation methods, and oversight around measurable cognitive capability instead of commercial gain, we can build systems that genuinely understand and think across domains, not just sophisticated tools performing as if they do.
If you find this content valuable, please share it with your network.
🍊 Follow me for daily insights.
🍓 Schedule a free call to start your AI Transformation.
🍐 Book me to speak at your next event.
Chris Hood is an AI strategist and author of the #1 Amazon Best Seller “Infailible” and “Customer Transformation,” and has been recognized as one of the Top 40 Global Gurus for Customer Experience.